| layout | article | ||
|---|---|---|---|
| title | Your Daily (or Maybe Monthly) Dose of | ||
| key | page-mlwatch | ||
| aside |
|
Synced: Google & DeepMind Study the Interactions Between Scaling Laws and Neural Network Architectures
Google AI: Towards Reliability in Deep Learning Systems
Google AI: Deep Hierarchical Planning from Pixels
MARKTECHPOST: IBM Researchers Showcase an Image Classifier Pretrained on Synthetic Data and Fine-Tuned on Real Data for Tasks, Did as Well as One Trained Exclusively on ImageNet’s Database of Real-World Photos
MARKTECHPOST: AI Researchers From China Introduce a New Vision GNN (ViG) Architecture to Extract Graph Level Feature for Visual Tasks
MARKTECHPOST: MIT Researchers Developed Tools to Help Data Scientists Make the Features Used in Machine-Learning Models More Understandable for End-Users
MARKTECHPOST: Researchers from George Mason and Emory University Develop ‘RES’: a Robust Python Framework for Learning to Explain DNNs (Deep Neural Networks) with Explanation Supervision
Synced: NVIDIA’s Global Context ViT Achieves SOTA Performance on CV Tasks Without Expensive Computation
MARKTECHPOST: Google Research Proposes MaskGIT: A New Deep Learning Technique Based on Bi-Directional Generative Transformers For High-Quality and Fast Image Synthesis
MARKTECHPOST: This Latest Paper From Twitter and Oxford Research Shows That Feature Propagation is an Efficient and Scalable Approach for Handling Missing Features in Graph Machine Learning Applications
Synced: DeepMind Proposes Symmetry-Based Representations as a Fundamental Principle for Learning Good Representations in General Intelligence
Synced: Microsoft’s FocalNets Replace ViTs’ Self-Attention With Focal Modulation to Improve Visual Modelling
MARKTECHPOST: MIT Researchers Suggest That a Certain Type of Robust Computer-Vision Model Perceives Visual Representations Similarly To The Way Humans Do Using Peripheral Vision
MARKTECHPOST: MIT Researchers Developed A Machine-Learning Model To Generate Extremely Realistic Synthetic Data That Can Train Another Model For Downstream Vision Tasks
MARKTECHPOST: LinkedIn Researchers Open-Source ‘FastTreeSHAP’: A Python Package That Enables An Efficient Interpretation of Tree-Based Machine Learning Models
MARKTECHPOST: CMU Researchers Introduce a Method for Estimating the Generalization Error of Black-Box Deep Neural Networks With Only Unlabeled Data
Google AI: Robust Graph Neural Networks
Synced: Google Researchers Propose a Novel Method, Called Constrained Instance reWeighting (CIW), To Reduce Noisy Labels in Deep Neural Networks
MARKTECHPOST: A New Deep Learning Study Investigate and Clarify the Intrinsic Behavior of Transformers in Computer Vision
Synced: Microsoft Improves Transformer Stability to Successfully Scale Extremely Deep Models to 1000 Layers
Synced: Jeff Dean Co-authors Guidelines for Resolving Instability and Quality Issues in the Design of Effective Sparse Expert Models
Synced: DeepMind & UCL Propose Neural Population Learning: An Efficient and General Framework That Learns Strategically Diverse Policies for Real-World Games
Synced: UC Berkeley, Waymo & Google’s Block-NeRF Neural Scene Representation Method Renders an Entire San Francisco Neighbourhood
Google AI: An International Scientific Challenge for the Diagnosis and Gleason Grading of Prostate Cancer
MARKTECHPOST: UT Austin Researchers Demonstrate a Deep Learning Technique That Achieves High-Quality Image Reconstructions Based on MRI Datasets
MARKTECHPOST: In A Latest Computer Vision Research, Researchers Introduce ‘JoJoGAN’: An AI Method With One-Shot Face Stylization
Google AI: Nested Hierarchical Transformer: Towards Accurate, Data-Efficient, and Interpretable Visual Understanding
MARKTECHPOST: MIT Researchers Introduce a Machine Learning Technique that can Automatically Describe the Roles of Individual Neurons in a Neural Network with Natural Language
MARKTECHPOST: A New AI Research Propose ‘UniFormer’ (Unified transFormer) to Unify Convolution and Self-Attention for Visual Recognition
MARKTECHPOST: Meta AI Research Proposes ‘OMNIVORE’: A Single Vision (Computer Vision) Model For Many Different Visual Modalities
MARKTECHPOST: Latest Research Based On AI Building AI Models
MARKTECHPOST: Researchers Introduce ‘SimpleBits’: An Information-Reduction Strategy That Learns To Synthesize Simplified Inputs For Neural Network Understanding
⭐ Google AI: Controlling Neural Networks with Rule Representations
MARKTECHPOST: Meta AI Introduces ‘Data2vec’ : A Self-Supervised Algorithm That Works For Speech, Computer Vision, and NLP
⭐ Synced: Yann LeCun Team’s Neural Manifold Clustering and Embedding Method Surpasses High-Dimensional Clustering Algorithm Benchmarks
MARKTECHPOST: CMU’s Latest Machine Learning Research Analyzes and Improves Spectral Normalization In GANs
Synced: New Study Revisits Laplace Approximation, Validating It as an ‘Effortless’ Method for Bayesian Deep Learning
MARKTECHPOST: Researchers at Meta and the University of Texas at Austin Propose ‘Detic’: A Method to Detect Twenty-Thousand Classes using Image-Level Supervision
⭐ MARKTECHPOST: Deepmind Researchers Propose ‘ReLICv2’: Pushing The Limits of Self-Supervised ResNets
MARKTECHPOST: Latest MIT Research To Test Whether Popular Methods For Understanding Machine Learning Models Are Working Correctly
Synced: Pushing the Limits of Self-Supervised ResNets: DeepMind’s ReLICv2 Beats Strong Supervised Baselines on ImageNet
⭐Synced: Facebook AI & UC Berkeley’s ConvNeXts Compete Favourably With SOTA Hierarchical ViTs on CV Benchmarks
MARKTECHPOST: Meta AI and CMU Researchers Present ‘BANMo’: A New Neural Network-Based Method To Build Animatable 3D Models From Videos
MARKTECHPOST: Researchers From Stanford and NVIDIA Introduce A Tri-Plane-Based 3D GAN Framework To Enable High-Resolution Geometry-Aware Image Synthesis
MARKTECHPOST: Researchers Propose Mitigation Strategies to Tackle Overinterpretation of Deep Learning Methods
MARKTECHPOST: ETH Zurich Team Introduce Exemplar Transformers: A New Efficient Transformer Layer For Real-Time Visual Object Tracking
Synced: Fujitsu AI, Tokyo U & RIKEN AIP Study Decomposes DNNs Into Modules That Can Be Recomposed Into New Models for Other Tasks
Synced: Advancing Deep Learning With Collective Intelligence: Google Brain Surveys Recent Developments
MARKTECHPOST: MIT Researchers Propose Patch-Based Inference to Reduce the Memory Usage for Tiny Deep Learning
Google AI: Google Proposes a ‘Simple Trick’ for Dramatically Reducing Transformers’ (Self-)Attention Memory Requirements
Synced: DeepMind’s RETRO Retrieval-Enhanced Transformer Retrieves from Trillions of Tokens, Achieving Performance Comparable to GPT-3 With 25× Fewer Parameters
⭐MARKTECHPOST: AI Researchers Propose ‘GANgealing’: A GAN-Supervised Algorithm That Learns Transformations of Input Images to Bring Them into Better Joint Alignment
TechTalks: Why we must rethink AI benchmarks
Google AI: Google at NeurIPS 2021
⭐ Synced: Warsaw U, Google & OpenAI’s Terraformer Achieves a 37x Speedup Over Dense Baselines on 17B Transformer Decoding
Synced: NeurIPS 2021 Announces Its 6 Outstanding Paper Awards, 2 Datasets and Benchmarks Track Best Paper Awards, and the Test of Time Award
⭐MARKTECHPOST: Microsoft Researchers Unlock New Avenues In Image-Generation Research With Manifold Matching Via Metric Learning
MARKTECHPOST: Google Research Open-Sources ‘SAVi’: An Object-Centric Architecture That Extends The Slot Attention Mechanism To Videos
MARKTECHPOST: Apple Researchers Propose A Method For Reconstructing Training Data From Diverse Machine Learning Models By Ensemble Inversion
Synced: Microsoft Asia’s Swin Transformer V2 Scales the Award-Winning ViT to 3 Billion Parameters and Achieves SOTA Performance on Vision Benchmarks
MARKTECHPOST: Imperial College London Researchers Propose A Novel Randomly Connected Neural Network For Self-Supervised Monocular Depth Estimation In Computer Vision
Synced: SPANN: A Highly-Efficient Billion-Scale Approximate Nearest Neighbour Search That’s 2× Faster Than the SOTA Method
Synced: Google Brain & Radboud U ‘Dive Into Chaos’ to Show Gradients Are Not All You Need in Dynamical Systems
MARKTECHPOST: DeepMind Researchers Present The ‘One Pass ImageNet’ (OPIN) Problem To Study The Effectiveness Of Deep Learning In A Streaming Setting
⭐Synced: A Leap Forward in Computer Vision: Facebook AI Says Masked Autoencoders Are Scalable Vision Learners
Google AI: Model Ensembles Are Faster Than You Think
MARKTECHPOST: MIT AI Researchers Introduce ‘PARP’: A Method To Improve The Efficiency And Performance Of A Neural Network
MARKTECHPOST: Researchers Propose ‘Projected-GANs’, To Improve Image Quality, Sample Efficiency, And Convergence Speed
Synced: Washington U & Google Study Reveals How Attention Matrices Are Formed in Encoder-Decoder Architectures
⭐MARKTECHPOST: MIT Researchers Propose A New Method To Prevent Shortcuts In Machine Learning Models By Forcing The Model To Use More Data In Its Decision-Making
MARKTECHPOST: Researchers Introduce ‘AugMax’: An Open-Sourced Data Augmentation Framework To Unify The Two Aspects Of Diversity And Hardness
Keywords: Multi-task learning, meta-learning
Summary:

MARKTECHPOST: Hugging Face Introduces “T0”, An Encoder-Decoder Model That Consumes Textual Inputs And Produces Target Responses
MARKTECHPOST: CMU AI Researchers Present A New Study To Achieve Fairness and Accuracy in Machine Learning Systems For Public Policy
MARKTECHPOST: AI Researchers From Huawei and Shanghai Jiao Tong University Introduce ‘CIPS-3D’: A 3D-Aware Generator of GANs
Synced: Yann LeCun Team Challenges Current Beliefs on Interpolation and Extrapolation Regarding DL Model Generalization Performance
⭐Synced: StyleNeRF: A 3D-Aware Generator for High-Resolution Image Synthesis with Explicit Style Control
keywords: underspecification
Summary:
- underspecification: a key failure mode especially prevalent in modern ML systems
- Identifying Underspecification in Real Applications
- Underspecification in Computer Vision
- Underspecification in Other Applications
MARKTECHPOST: Researchers at ETH Zurich & Microsoft Introduce ‘PixLoc’: A Neural Network For Feature Alignment With A 3D Model Of The Environment
Synced: ICCV 2021 Best Papers Announced
[Swin Transformer] [Mip-NeRF] [OpenGAN] [Viewing Graph Solvability] [Common Objects in 3D] [Pixel-Perfect Structure-from-Motion]
⭐ Synced: Are Patches All You Need? New Study Proposes Patches Are Behind Vision Transformers’ Strong Performance
⭐ Synced: Apple Study Reveals the Learned Visual Representation Similarities and Dissimilarities Between Self-Supervised and Supervised Methods
⭐Synced: Google Significantly Improves Visual Representations by Adding Explicit Information Compression
⭐ Google AI: Efficient Partitioning of Road Networks
⭐ DeepMind: Nowcasting the Next Hour of Rain
MARKTECHPOST: University of Oxford Researchers Release ‘PASS’ Dataset With 1.4M+ Images (Free From Humans) For Self-Supervised Machine Learning
Synced: UMass Amherst & Google Improve Few-Shot Learning on NLP Benchmarks via Task Augmentation and Self-Training
⭐Google AI: Pathdreamer: A World Model for Indoor Navigation
Keywords: indoor navigation
Comment: Super Cool!
[paper1: EfficientNetV2] [paper2: CoAtNet] [code]
Keywords: neural architecture search;
Comment: Super Cool!
Synced: UC Berkeley Uses a Causal Perspective to Formalise the Desiderata for Representation Learning
Keywords: representation learning; non-spuriousness; disentanglement
Comment: Too much terminology that I don‘t understand. Mark and read it later.
MARKTECHPOST: Israeli Researchers Unveil DeepSIM, a Neural Generative Model for Conditional Image Manipulation Based on a Single Image
Comment: Experiment results are astonishing. Mark and read later.
[project page] [paper] [partially supervised segmentation paper]
Keywords: instance segmentation; partially supervised instance segmentation
Summary:
Instance segmentation is an important task to many downstream applications. Collecting large labeled instance segmentation dataset is time consuming. Partially supervised instance segmentation target to tackle the challenge but requires a stronger form of model generalization to handle novel classes not seen at training time. This paper proposed two easy-to-implement fixes (one training protocol fix, one mask-head architecture fix) based on Mask R-CNN like network that work in tandem to close the gap to fully supervised performance. While neither of these ingredients have a large impact on the classes for which masks are available during training, employing both leads to significant improvement on novel classes for which masks are not available during training. In a nutshell, cropping exclusively to ground true boxes during training and using deep hourglass mask heads with 50 or more layers brought significant performance improvement to unseen classes.
Comment: I haven't read the paper yet. I hope there will be more discussion about why these two fix would bring better performance to unseen classes. Otherwise it's just a technical report.
Keywords: Automatic speech recognition (ASR)
Summary:
With over 1 million utterances, Euphonia’s corpus is one of the largest and most diversely disordered speech corpora (in terms of disorder types and severities) and has enabled significant advances in ASR accuracy for these types of atypical speech. The results demonstrate the efficacy of personalized ASR models for recognizing a wide range of speech impairments and severities, with potential for making ASR available to a wider population of users.
[paper1] [paper2: CutPaste] [code]
Keywords: anomaly detection; self-supervised learning; one-class classification
Summary:
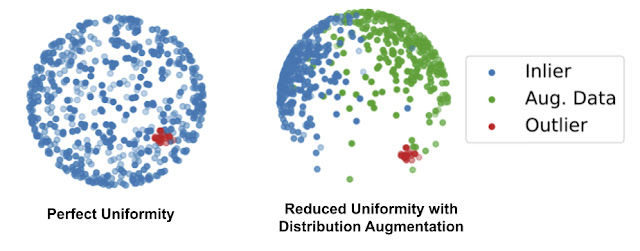
The assumption of anomaly detection or the abstract of the problem one-class classification is that you have a large amount of normal examples and only a few anomalous data. The first paper aims to combine traditional one-class classifier with self-supervised learning for feature extraction. A distribution augmentation (DA) method is proposed to separate outlier from inlier while contrastive learning tend to spread out normal examples uniformly on a sphere.
The second paper is designed a cut and paste method for self-supervised learning.
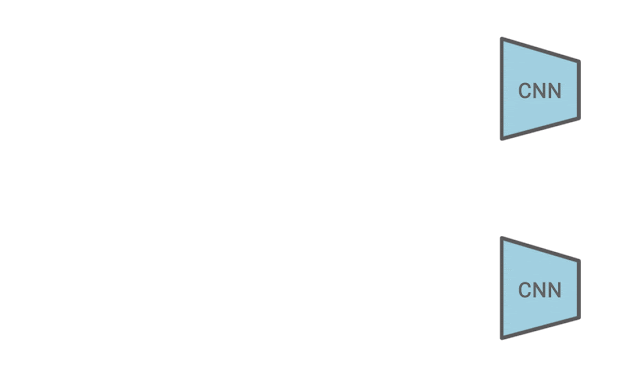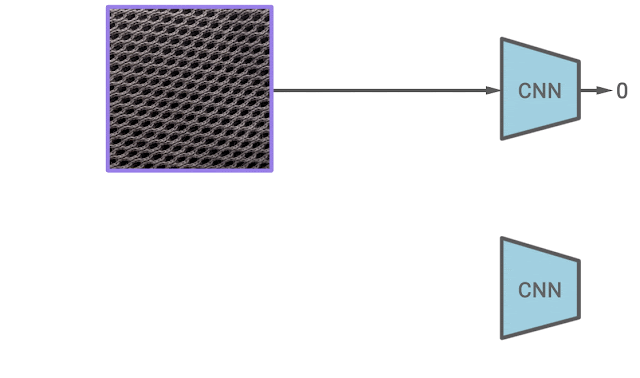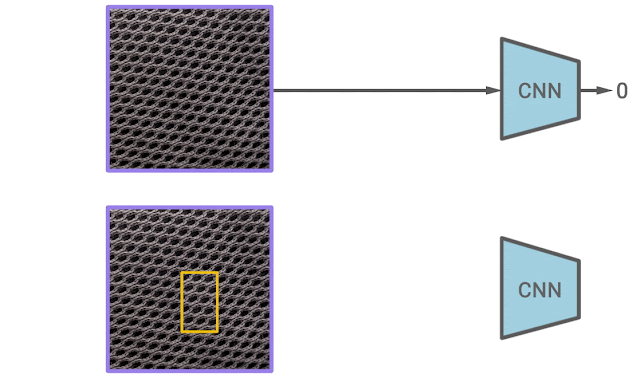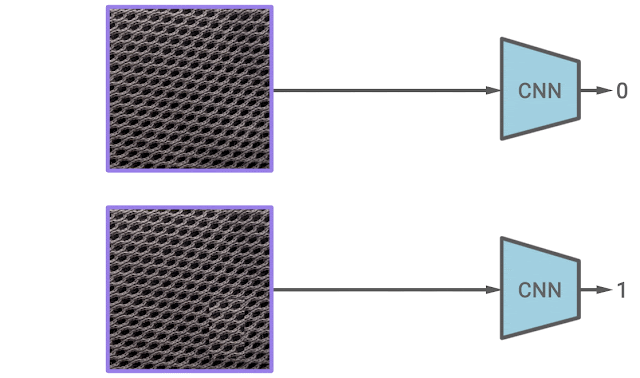
Comment: With a fast glance of the blog, the idea of combining one-class classifier with self-learning feature extractor is trivial. The proposed distribution augmentation (DA) to separate outliers from inlier is interesting but lack of persuasion because the situation when both inliers and augmented data are uniformly spread out on a sphere isn't excluded. The second paper is more of an adaptation for defect detection of the first paper.
Keywords: data-centric
Summary:
MLOps’ most important task: Ensure consistently high-quality data in all phases of the ML project lifecycle. Good data is:
- Defined consistently (definition of labels y is unambiguous) • Cover of important cases (good coverage of inputs x)
- Has timely feedback from production data (distribution covers data drift and concept drift)
- Sized appropriately
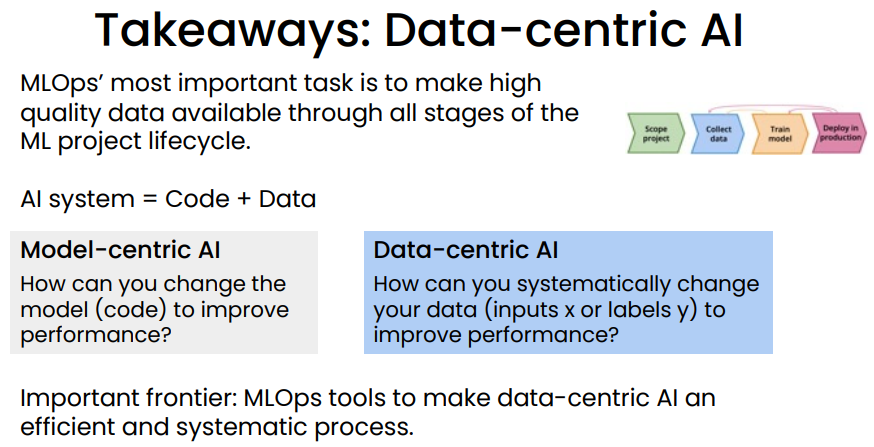
Comment: Like Andrew said in the webinar, we took 80% of time preparing high quality data but only 1% of AI research is about data. It would be more encouraging to see more researches about how data quality affect model performance.
⭐OpenAI: CLIP: Connecting Text and Images
⭐OpenAI: DALL·E: Creating Images from Text
⭐OpenAI: Image GPT
Posted by u/sql-gumby
I’m trying to come up with some best practices when using PostgreSQL for the DS team. We’ve had a couple of projects using SQL DBs as training data sources for deep learning (DL) with upwards of 1TB of data. Note that in these projects, the training data very rarely changes or gets updated over the course of the project - for training, we typically isolate a large pool of data from any live applications. One major benefit over other storage approaches (e.g. file system) we’ve seen is the straightforward range query syntax for time series data, e.g.
SELECT ts, col1, ..., colN FROM some_table WHERE ts >= ? AND ts <= ?useful when sampling contiguous time series blocks of some variable length during batch generation. When working, e.g. with files, the same functionality can be tricky to implement if the data is not nicely structured. On the other hand, we did have a lot of issues when using the DB:
- Slow queries if the data is very large, even with the appropriate indices in place
- Zombie queries / processes on the DB (possibly caused by prematurely terminated training loops), eventually needing a DB restart
- A lot of time spent on ingesting the data, optimising the queries, data layout and DB maintenance
which leads me to believe that using the DB doesn’t really pay off, especially when the data is really large. It seems like even rolling a bespoke storage and query approach on top of a file system is better for performance and maintainability.
Does anybody have examples of DL projects where a SQL data store does make sense even with large data?
My company uses postgres as a training data backend and works with very large NLP and Vision datasets. When running experiments we don't interface with the database directly though: we typically trigger exports and work with those flat files in our experiments until we need to refresh for some reason.
Comments like
Zombie queries / processes on the DB (possibly caused by prematurely terminated training loops), eventually needing a DB restart
make me think the problem is probably on the implementation side. RDBs scale incredibly well if used properly. Do you have someone on your team with RDB DBA chops that can help you investigate why it is not performing? Reddit will not be able to help you diagnose such a vague question
r/MachineLearning: [D] 5 considerations for Deploying Machine Learning Models in Production – what did I miss?
Posted by u/mgalarny
I wrote a post about considerations for deploying machine learning models in production. Below are the considerations. What did I not consider? I know the first consideration seems obvious, but I thought it was worth mentioning.
So:
- You do not need feature store, unless your model depends on real time feature values , I.e. values that occurred after the model was trained. Those are usually relate to time based information.
- You missed model fairness and bias measurements.
- You missed progressive deployment. Usually models are deployed in shadow mode or canary mode. This way you can compare the new model to the old model, before promotion.
- I would also recommend having some sort of a CD pipeline, such that the models are tested in production like env (e.g. staging) before placing them in production.
- Within the CI/CD you should design ML specific unit tests.
- Regarding monitoring, you should also monitor you data sources - e.g. general data quality, as well as latency, health, etc.
- You should have a mechanism such that models can be rolled back to previous versions.
- Note that there are two kinds of productions: real time and batch. Depending on your use case, you might want to consider your points as they relate to the batch use case.
r/MachineLearning: [D] Measure the distance between two domains for transfer learning.
No, this is actually an active research area. You are, roughly asking, suppose you want to minimize F_P(t) := E_P[f(t, z)], in the parameter t. But instead you have samples Z ~ Q, where Q is not equal to P. Your question boils down to "how easy is it to optimize F_P(t), given sample access to Q"?.
Of course some type of assumptions on the loss f, parameter space that t lies in, and the distribution pair (P, Q) will be necessary to make progress. Your question suggests one popular one, called covariate shift or domain adaptation, where Z = (X, Y) and the conditional distribution Y | X is fixed (i.e., it is the same) under P and Q, but the distribution on X is allowed to vary.
To my knowledge there is not yet an established metric of difficulty in the above described situation. As you can imagine, it will not just depend on P, Q, but rather also the type of task being addressed (e.g., if f is a square loss, and t is a linear functional on the data, then this is like estimating a linear model with a different distribution on the covariates, so you would roughly expect the complexity to scale in tr(Cov_Q^{-1} Cov_P), where here tr is trace, and Cov_D is the expectation E_D[X X^T]. This is d (the dimension of the covariates) when P = Q.)
You might also see: https://arxiv.org/pdf/1803.01833.pdf, this paper introduces one notion called the "transfer exponent".
r/MachineLearning: [D] What do Machine Learning Engineers at Facebook do?
I can speak to my observed experience of the difference between three broad categories of Machine Learning adjacent roles that I imagine exist at a company like Facebook:
Machine Learning Engineer (MLE): This is more of a software engineering "like" role. You work on writing internal tools (sometimes that get open-sourced) and creating machine learning pipelines and infrastructure. So for example you may have the task of appropriately designing and optimizing the ways in which data gets stored, loaded, and preprocessed in order or something like trying to optimally parallelize training jobs to tune hyperparameters and architectures, some of your responsibilities might be making sure that the model is packaged and deployed appropriately so that infra/DevOps teams can monitor and adequately control it so that it interacts with the appropriate interfaces that use those models
Data Scientist (DS): Your job is more about very solving specific business problems with data. I know through friends that have this position, that at Facebook they do a lot of their work in Jupyter Notebooks, for the ease of sharing the results with say other DSs and MLEs. With Facebook (as with many larger tech companies) a lot of your work is going to be on building models for predict customer behavior in terms of advertisement engagement. Depending on your seniority you will get to propose and choose different approaches and data sources, but ultimately your models are a part of the product you're selling for FB ads services so you'll be doing lots of A/B tests and evaluating the results, and you will need to be able to "deliver" and spend a fair amount of your time explaining your approaches
Research Scientist (RS): You work with Facebook's AI Research group, you present novel methods and approaches that will broadly focus on delivering and solving FB business problem but generally you get a little more flexibility and creative freedom to try new stuff. Your time is spent working on implementing your research and then often working with MLEs to set up your experiments after you have some initial proof of concept done. It's a little more open-ended than the DS position, but if your results are promising you might find that your also working with DSs to see your working go into production.
Hope this helps, but I recommend looking at the different roles they have on their job sites and also look for similarly titled positions at comparably sized companies, these often have a tremendous amount of overlap.
As others have mentioned though the recruiter will likely be able to answer your questions as well.
r/MachineLearning: [D] How would you deploy an optimization type model? ex: CLIP+VQGAN
I actually spent other a month back in February setting something like that up.
It's definitely doable, but for me the biggest issue was too slow startup times in EC2 instance for scaling.
After a lot of optimization it would still take 4 minutes from requesting an instance to generation starting, which was too long to be practical for me
These are not scalable examples but I spent the last week hacking on two prototypes for hosting vqgan+clip which might be helpful
- https://github.com/gramhagen/imagen - a unity application that hits a back-end server hosting vqgan+clip model
- https://github.com/gramhagen/image - a streamlit application for interacting with a vqgan+clip model
Thoughts for how you might scale this would be to serve this model using something like Ray Serve on a cluster of workers with GPUs. you still need to handle asychronous requests though because the inference time is going to be too long unless you have a really small image and limited iterations. The hacky way I did it was just respond to the initial request with an id, and then have a second endpoint that retrieves images once they are ready.
r/datascience: Interviewing Red Flag Terms
Posted by [Job Search](https://www.reddit.com/r/datascience/search?q=flair_name%3A"Job Search"&restrict_sr=1)
Phrases that interviewers use that are red flags.
So far I’ve noticed:
- Our team is like the Navy Seals in within the company
- work hard play hard
- (me asking does your team work nights and weekends): We choose to because we are passionate about the work
r/MachineLearning: [D] Has the ResNet Hypothesis been debunked?
Posted by
The ResNet architecture was invented to solve the degradation problem that has been empirically seen in Very Deep Neural Networks i.e. “34-layer plain net has higher training error throughout the whole training procedure, even though the solution space of the 18-layer plain network is a subspace of that of the 34-layer one.“
[
The natural presumption is that this problem is caused by the Vanishing Gradient Problem which has been observed in Recurrent Neural Networks and, to a lesser extent, in Long-Short Term Memory Networks. But the authors of the paper argue that this is, most likely, not the case:
We argue that this optimization difficulty is unlikely to be caused by vanishing gradients. These plain networks are trained with BN [16], which ensures forward propagated signals to have non-zero variances. We also verify that the backward propagated gradients exhibit healthy norms with BN. So neither forward nor backward signals vanish. In fact, the 34-layer plain net is still able to achieve compet- itive accuracy (Table 3), suggesting that the solver works to some extent. We conjecture that the deep plain nets may have exponentially low convergence rates, which impact the reducing of the training error3. The reason for such optimization difficulties will be studied in the future.
I will refer to this as the “ResNet Hypothesis”.
Many recent papers and tutorials appear to be assuming that the ResNet Hypothesis is false. I have read numerous papers in which the authors add skip connections in order to “improve gradient flow” and they cite the original ResNet paper to support this claim. While it is quite plausible that adding skip connections will improve gradient flow, what caused the degradation problem in the first place? The idea that skip connections solve the degradation problem by improving gradient flow seems to be in clear contradiction with the ResNet Hypothesis; so where did this idea come from? Has the ResNet Hypothesis been
debunkedfalsified***?***Edit 1 - I think this is an accurate representation of the average DL researcher’s (myself included) understanding of why ResNets work [based on u/impossiblefork’s answer]:
[
Edit 2 - Apologies for using the word ”debunked” in the original post. Quite irresponsible of me in hindsight. Thanks to /u/ComplexColor for pointing it out. Unfortunately I am unable to edit the title.
Shortcut connections improve the loss landscape; they make optimization much easier. There is a lot of research to back this up, but the two main papers that come to mind are
- The Shattered Gradients Problem: If resnets are the answer, then what is the question? (ICML 2017) shows that ResNets have much more stable gradients.
- Visualizing the Loss Landscape of Neural Nets (NeurIPS 2018) again shows that ResNets have a smoother loss surface (Figure 1 in that paper is the 1-picture-answer of your question).
You don't need shortcuts to learn effective representations, but optimization will be harder. For example, Fixup Initialization: Residual Learning Without Normalization (ICLR 2019) shows that if you are careful about initialization, you can train ResNets without shortcuts to good results. RepVGG: Making VGG-style ConvNets Great Again (CVPR 2021) shows that you can remove shortcuts after training and still have a good network.
This is, BTW, still somewhat in line with the original idea of ResNet: You initialize each block as an identity function, so initially it almost appears as if the parameters aren't actually there / aren't doing anything. And then you gradually move away and have the effect of the block come into play.
![r/MachineLearning - D] Has the ResNet Hypothesis been debunked?](https://preview.redd.it/7todt74s18q71.png?width=1314&format=png&auto=webp&s=0a1af475ef27fd8355d1527223e74556c6a993e9)
![r/MachineLearning - D] Has the ResNet Hypothesis been debunked?](https://preview.redd.it/wbvvkwlrd8q71.png?width=724&format=png&auto=webp&s=7b3cac7d8baea007d9dd379ce67020a5a65e2c9b)
r/MachineLearning: [D] What are some ideas that are hyped up in machine learning research but don't actually get used in industry (and vice versa)?
Cool in industry but not cool in research: Cleaning datasets, going from dev to prod (and all the research to improve these processes)
Cool in research but not cool in industry: Adversarial attacks
just my opinion
About adversarial attacks in production: company wanted to insert adversarial noise in car sale ads posted on their site in order to break their competitors data scraping model (competitors just copied data from the original site). I think that’s awesome!
The original article is in Russian, but the images are quite illustrative, try google translate
https://habr.com/ru/company/avito/blog/452142/
UPD: noise was inserted in photos, competitors tried to replace the watermark with theirs
r/datascience: Putting ML models in production
The topic is complex, which is why there are multiple job roles that specialize in production and deployment. Some of them are Data Engineer, Infrastructure Software Engineer, and ML Engineer.
How to productionize and deploy depends on what the model is doing and how it needs to get its data. On the input side there is batch, micro-batch, streaming, and REST. On the output side there is outputting to a DB, returning a REST request, creating a dashboard, and creating a report.
All of these have different requirements. Furthermore, training and testing on your local machine may not be big data, but say the company grows to have enough customers it becomes big data in prod. Suddenly you realize you should have been using different tools the entire time.
There are different services that aid the functionality of productionization and deployment. All of them have their strengths and weaknesses. I like to think of them as a spectrum between how much they handle the low level data engineering work for you to how bare metal they are. The ones that make life easiest may lack functionality you need, or may cost the most. The ones that are the most bare metal you can do anything and everything in but you have to setup an entire ecosystem of servers and pipes to get it all done becoming a full time job. Also, you need someone on call if a server goes down or breaks. This is why you want at least one Data Engineer, ML Engineer, Infrastructure Engineer, DevOps, or MLOps for the extreme situations where the server is on fire and someone who appropriately needs to handle that situation to minimize downtime.
On the easiest to use side is Domino's Data Labs. It supports everything except dynamic scaling of Spark clusters on a heavy load, so if you're very big data it may not support it.
On the next easiest but more powerful is Databricks. Already you're looking at a product designed to be learned before used. Databricks uses Spark, so it's designed for big data but is not necessary.
Next easiest is the competition, like AWS Sagemaker. Out of the box the default functionality is more limited on these kinds of offerings unless you expand to using their entire ecosystem. How do you know what to parts of their ecosystem to choose that is right for you? Study alone typically doesn't do it by this point, you have to talk to an AWS rep, possibly multiple, and they will try to help you out.
At the bottom is straight bare metal. Spin up your own servers in the cloud, install the necessary parts, and set it up yourself. The upside is this at first seems less complex. The downside is you're not forced to use best practices which will cause a lot of headaches down the road. You'll have a lot of limited functionality you didn't know could exist if you didn't use one of the offerings above that bundle tools together for you.
Posted by u/jehan_gonzales
I moved on from analytics two years ago and became a product manager.
I was a data analyst for four years.
- Almost two years in market research with survey data building statistical models (mainly linear and logistic regression) in SPSS and Excel (with a bit of R here and there)
- Nine months managing a SQL database where I was meant to be analysing the data but was mainly debugging a very bad production environment
- 1.5 years as a data analyst in product analytics where I worked with retail sales and loyalty program data. I spent the first year doing data governance stuff with the client but later moved into an ML team and tried to figure out insights for end users without them having to search for them.
Since becoming a product manager, I can still work with data and do the interesting analysis but then I spend most of my time using the numbers to drive decisions and if there is anything that requires long, time consuming ETL tasks, I can farm them out.
So far, it's been a great move as I've always been more interested in decision science rather than writing code for the sake of it (I enjoy it in moderation but find more meaning using analysis to get shit done).
I was wondering, have any of you moved out of analytics and data science? What prompted the move? Or are you thinking about changing industries?
Always interesting to hear from other people at the coalface.
Posted by u/the75th
Been seeing a lot of posts recently of people being hired to do data science and ending up in, from a data point of view, suboptimal work places. In my opinion many of these places had red flags from to get go based on the description of the company they gave.
My main advice is to be as critical to the company as they are to you:
Screen their job posting with as much rigour as they screen your CV trying to get a sense of what you'll really be doing irrespective of your 'data scientist' job title. Typical red flags for me would be (not exhaustive):
- No mention of cloud related tooling.
- SQL and data warehousing featuring more promintently than anything else. Reason being that if I wanted to do a DA job, which I really enjoyed from past experiences, I would just apply for that.
- No mention of any kind of version control.
- "Use whatever tools and languages you want on the job". This one is very particular but to me that would indicate no standardisation, probably a lot of csv files, excel users, ad-hoc analysis on notebooks and very little being put into production / automated. This might be a pet peeve but I believe in many cases long term value from data can't just be done through ad-hoc analyses and 99 % of companies aren't mature enough to let everyone use their own tools without it becoming an unmaintanable mess.
- No mention of anything casual. This one is personal, colleagues are colleagues and not necessarily friends but a workplace with a few social amenities would make being 8-9 hours in the office more bearable.
Not all of the information you value can be gotten from the job posting so the next step would be to think about what you value ahead of the interview and ask them in a polite manner. Job interviews should be as much of you deciding if they are a fit for you as vice versa.
This may help you to uncover small details that can help you decide picking one offer over the other. Even if you only have 1 offer knowing what you're getting into in advance can help you make peace with / prepare for it.
If I discard all places with red flags, I will only be able to work for myself, which is not necessarily a bad thing, but may not be for everyone.
Note: as a freelancer, consultant, etc. you are still working for your clients, and they show red flags just the same.
WRT OPs red flags, I only agree on the second (SQL), as a freelancer / consultant you are expected to "be on your own" on those points, i.e. those are not red flags to me.
What are red flags for me? Off the top of my head:
- Unrealistic expectations (the parent of all): "we want you to build and train GPT-4 for us, for $5000, in two weeks".
- Micromanagement: "We have already decided what we are going to do and how we are going to do it. We want to hire you to apply linear regression to find a number between 3 and 5 that will magically make our decisions the right decisions. We do not know why the last 5 data scientists rejected to do a simple linear regression".
- Lack of maturity: "We do not have any data. We want to hire you do do data science for us. Any advanced enough technology is like magic, we want you to show us your divination powers."
r/datascience: Data science even at mature companies can be a mixed bag.
Posted by u/compactsupport
Earned a full time position at a bank in their Financial Crime team preventing traders from manipulating the market. They said they had lots of data (they do) and wanted to incorporate some machine learning into their business. Sweet, I'm in.
Its been rough. The team is a year old, they are mostly focused on making the product work rather than anything else, everything is run through KX and the q language (which is cool if you're into trading but a nightmare if you want to do analytics or ML).
I've been given extremely easy to answer questions but the business insists I use ML because that's why they hired me. "Tell me when a trader makes a trade in a new sector" -- my guy, that is a look and not a problem for machine learning. I'd love to answer these questions, but because I'm at a bank things are extremely slow to move on anything. Getting a data store for analytics is a months long endeavour leaving me to use .csv files. I can't scale that.
Gets better. I tried asking to talk to some of the people using our product so I could identify pain points and how we could solve that. Got a big fat "NOPE" and actually initiated an argument between my manager and the business owner.
There is also nowhere for us to centralize our analytics work. No feature store, no data science sandbox, no data engineering to give us up to date info. I don't even have access to production data! All I get is staging which I have been assured is fit fur purpose \s.
I'm frustrated. Its been 5 months or so, I think that is long enough to say "hey, not a good fit" and maybe find another position. Its a real shame because I worked in a different team at the same bank and they were much more mature with respect to data science.
r/MachineLearning: [Discussion] How to present machine learning projects to domain experts without ML background?
I do thos frequently in my current job. The key is to get them interested in the problen and the solution.
At a very high level, first convey these points briefly:
- The use case (what was the user workflow like before)
- The problem or the bottleneck or what you couldnt do before.
- Why and how the problem affects the user workflow (or why should i care )
- Mention that you have solved / addressed / bettered it
- Why no one else has solved it or why it is a hard problem
- So how did we do it ? A laymans menton of what the solution is
So now they are hooked. You can now do a deep dive.
Ideally a highly archtectural / flowchart of each module in the splution helps set the visual grounding needed to understand a deep technical solution.
Then begin the deepdive. Tie every aspect of the deepdive with which module in the flowchart you're in.
Lastly, assume your audience knows nothing. This leads to issues with runtime of the presentation. So my solution is to always have hidden faqs and explainer slides ready if needed. Read the room as you go and stop frequently for questions. This way you can keep up a good pace, and slowdown if there are a lot of question or even worse No Questions.
Lqstly, qlways have a takeaways slide. After a 1 hr presentation some peoples brains are fried. So you want them to take the main takeaways even if they zoned out at some point. It also makes them feel like they took something awayy from the presentation and makes them more likely to attend future ones.
Hope this helps.
r/datascience: Any Data Scientists here working for Microsoft or Amazon?
I joined Amazon as a Data Scientist a few months ago in NYC.
- What kinds of projects are you working on as a data scientist? Have you ever seen a product on Amazon that has only one photo, no text, and looks "fake"? Our team is working to help sellers improve their product listings. Our team builds models that are trained on and score the entire Amazon catalogue. We serve recommendations to sellers, e.g. "add 4+ photos". I'm currently building tracking to measure the impact of our product and concurrently performing causal inference studies on existing integrations.
- How have you grown as a data scientist since joining your company? I barely knew AWS services before I joined, and I've been learning these services left and right since then. I enjoy the software and data engineering aspect of DS. One perk of working for Amazon is that you get all the AWS access you need.
- How does your company measure success of your projects? No idea, but I don't think there's a simple answer. Generally speaking, it seems like you need to validate your own results and present them to a room of other scientists in what resembles peer review.
- How much corporate red tape do you have to deal with? Almost zero. It's actually quite remarkable. Amazon is notorious for moving fast and not requiring signoff or permission for most things. They actively promote "bias for action" within the company. As far as I can tell, it is part of the culture.
- How much autonomy do you have? (For example to pursue a hunch where there is a potential for improvement even if no one notices or cares) Lots. I'm treated far more senior than I was at my previous company. I report to one person and that's my manager. He listens to me on science topics and generally gives me ample control over what I am doing.
- What would you change about your company? Amazon has some legacy internal tooling (outside AWS) that can be quite painful to work with. I also wish it was easier to use open source. It's certainly possible, but not always as easy as it should be.
- What's the remote work policy? Atm, we are full remote. Starting in January, official policy from the top down is 3 days in, 2 days remote, although that might change.
- How's your work life balance? So far great, but I'm still new. I think the long term answer is good not great. It's better than a startup, but there are big scary deadlines that you need to meet. FYI being a DS is quite a bit better than being a Data Engineer, because you won't be on call.