-
k 近邻法(
k-Nearest Neighbor:kNN)是一种基本的分类与回归方法。- 分类问题:对新的样本,根据其 k 个最近邻的训练样本的类别,通过多数表决等方式进行预测。
- 回归问题:对新的样本,根据其 k 个最近邻的训练样本标签值的均值作为预测值。
-
k 近邻法==不具有显式的学习过程==,它是直接预测。它是“惰性学习”(
lazy learning)的著名代表。-
它实际上利用训练数据集对特征向量空间进行划分,并且作为其分类的"模型"。
-
这类学习技术在训练阶段仅仅将样本保存起来,训练时间开销为零,等到收到测试样本后再进行处理。
那些在训练阶段就对样本进行学习处理的方法称作“急切学习”(
eager learning)。
-
-
k 近邻法是个非参数学习算法,它没有任何参数(k 是超参数,而不是需要学习的参数)。
-
k 近邻模型具有非常高的容量,这使得它在训练样本数量较大时能获得较高的精度。
-
它的缺点有:
-
计算成本很高。因为需要构建一个$ N\times N$ 的距离矩阵,其计算量为
$O(N^{2})$ ,其中 N 为训练样本的数量。当数据集是几十亿个样本时,计算量是不可接受的。
-
在训练集较小时,泛化能力很差,非常容易陷入过拟合。
-
无法判断特征的重要性。
-
-
-
k 近邻法的三要素:
- k 值选择。
- 距离度量。
- 决策规则。
-
当 k=1 时的 k 近邻算法称为最近邻算法,此时将训练集中与$ \mathbf {\vec x}
$最近的点的类别作为 $ \mathbf {\vec x} $的分类。 -
k 值的选择会对 k 近邻法的结果产生重大影响。
-
若 k 值较小,则相当于用较小的邻域中的训练样本进行预测,"学习"的偏差减小。
只有与输入样本较近的训练样本才会对预测起作用,预测结果会对近邻的样本点非常敏感。
若近邻的训练样本点刚好是噪声,则预测会出错。即: k 值的减小意味着模型整体变复杂,易发生过拟合。
- 优点:减少"学习"的偏差。
- 缺点:增大"学习"的方差(即波动较大)。
-
若 k 值较大,则相当于用较大的邻域中的训练样本进行预测。
这时输入样本较远的训练样本也会对预测起作用,使预测偏离预期的结果。
即: k 值增大意味着模型整体变简单。
- 优点:减少"学习"的方差(即波动较小)。
- 缺点:增大"学习"的偏差。
-
-
应用中, k 值一般取一个较小的数值。通常采用交叉验证法来选取最优的 k 值。
-
特征空间中两个样本点的距离是两个样本点的相似程度的反映。
k 近邻模型的特征空间一般是 n 维实数向量空间$ \mathbb R^{n}$ ,k 其距离一般为欧氏距离,也可以是一般的
$L_p $ 距离:$$ L_p(\mathbf {\vec x}i,\mathbf {\vec x}j)=(\sum{l=1}^{n}|x{i,l}- x_{j,l}|^{p})^{1/p},\quad p \ge 1\ \mathbf {\vec x}i,\mathbf {\vec x}j \in \mathcal X=\mathbb R^{n};\quad \mathbf {\vec x}i=(x{i,1},x{i,2},\cdots,x{i,n})^{T} $$
- 当 p=2 时,为欧氏距离:$ L_2(\mathbf {\vec x}i,\mathbf {\vec x}j)=(\sum{l=1}^{n}|x{i,l}- x_{j,l}|^{2})^{1/2}$
- 当 p=1 时,为曼哈顿距离: $L_1(\mathbf {\vec x}i,\mathbf {\vec x}j)=\sum{l=1}^{n}|x{i,l}- x_{j,l}|$
- 当 p=$\infty$ 时,为各维度距离中的最大值:$ L_{\infty}(\mathbf {\vec x}i,\mathbf {\vec x}j)=\max_l|x{i,l}- x{j,l}|$
-
不同的距离度量所确定的最近邻点是不同的。
-
分类决策通常采用多数表决,也可以基于距离的远近进行加权投票:距离越近的样本权重越大。
-
多数表决等价于经验风险最小化。
设分类的损失函数为 0-1 损失函数,分类函数为$ f:\mathbb R^{n} \rightarrow {c_1,c_2,\cdots,c_K}。$
给定样本$ \mathbf {\vec x} \in \mathcal X
$,其最邻近的 k 个训练点构成集合$ \mathcal N_k(\mathbf {\vec x})。设涵盖 \mathcal N_k(\mathbf {\vec x}) $区域的类别为$c_m$ (这是待求的未知量,但是它肯定是$ c_1,c_2,\cdots,c_K $之一),则损失函数为:$$ L = \frac {1}{k}\sum_{\mathbf {\vec x}i \in \mathcal N_k(\mathbf {\vec x})}I(\tilde y_i \ne c_m)=1-\frac{1}{k}\sum{\mathbf {\vec x}i \in \mathcal N_k(\mathbf {\vec x})}I(\tilde y_i = c_m) $$ $L $就是训练数据的经验风险。要使经验风险最小,则使得 $\sum{\mathbf {\vec x}i \in \mathcal N_k(\mathbf {\vec x})}I(\tilde y_i = c_m) $最大。即多数表决:$c_m=\arg \max{c_m} \sum_{\mathbf {\vec x}_i \in \mathcal N_k(\mathbf {\vec x}) } I(\tilde y_i=c_m) $。
-
回归决策通常采用均值回归,也可以基于距离的远近进行加权投票:距离越近的样本权重越大。
-
均值回归等价于经验风险最小化。
设回归的损失函数为均方误差。给定样本$ \mathbf {\vec x} \in \mathcal X
$,其最邻近的$ k$个训练点构成集合$ \mathcal N_k(\mathbf {\vec x})。$设涵盖$ \mathcal N_k(\mathbf {\vec x})$ 区域的输出为$ \hat y $,则损失函数为:$$ L = \frac 1k\sum_{\mathbf {\vec x}i \in \mathcal N_k(\mathbf {\vec x})} (\tilde y_i - \hat y)^2 $$ L 就是训练数据的经验风险。要使经验风险最小,则有:$\hat y = \frac {1}{k}\sum{\mathbf{\vec x}_i\in \mathcal N_k(\mathbf{\vec x})}\tilde y_i$ 。即:均值回归。
-
k 近邻法的分类算法:
-
输入:
-
训练数据集$ \mathbb D={(\mathbf {\vec x}_1,\tilde y_1),(\mathbf {\vec x}_2,\tilde y_2),\cdots,(\mathbf {\vec x}_N,\tilde y_N)},\mathbf {\vec x}_i \in \mathcal X \subseteq \mathbb R^{n},\tilde y_i \in \mathcal Y={c_1,c_2,\cdots,c_K} $
-
给定样本$ \mathbf {\vec x}$
-
-
输出: 样本$ \mathbf {\vec x}$ 所属的类别 y
-
步骤:
- 根据给定的距离度量,在
$\mathbb D $ 中寻找与$ \mathbf {\vec x}$最近邻的 k 个点。定义涵盖这 k 个点的 $ \mathbf {\vec x}$ 的邻域记作$ \mathcal N_k(\mathbf {\vec x}) $。 - 从
$\mathcal N_k(\mathbf {\vec x}) $ 中,根据分类决策规则(如多数表决) 决定$ \mathbf {\vec x} $的类别$y :y=\arg \max_{c_m} \sum_{\mathbf {\vec x}_i \in\mathcal N_k(\mathbf {\vec x}) } I(\tilde y_i=c_m) 。$
- 根据给定的距离度量,在
-
-
k 近邻法的回归算法:
-
输入:
-
训练数据集
$\mathbb D={(\mathbf {\vec x}_1,\tilde y_1),(\mathbf {\vec x}_2,\tilde y_2),\cdots,(\mathbf {\vec x}_N,\tilde y_N)},\mathbf {\vec x}_i \in \mathcal X \subseteq \mathbb R^{n},\tilde y_i \in \mathcal Y \subseteq \mathbb R $ -
给定样本$ \mathbf {\vec x}$
-
-
输出:样本
$\mathbf {\vec x}$ 的输出 y -
步骤:
- 根据给定的距离度量,在$ \mathbb D
$中寻找与$ \mathbf {\vec x}$最近邻的 k 个点。定义涵盖这 k 个点的 $ \mathbf {\vec x}$ 的邻域记作$ \mathcal N_k(\mathbf {\vec x}) $。 - 从
$\mathcal N_k(\mathbf {\vec x}) $ 中,根据回归决策规则(如均值回归) 决定$\mathbf {\vec x} $ 的输出$y :y= \frac {1}{k}\sum_{\mathbf{\vec x}_i\in \mathcal N_k(\mathbf{\vec x})}\tilde y_i 。$
- 根据给定的距离度量,在$ \mathbb D
-
-
实现 k 近邻法时,主要考虑的问题是:如何对训练数据进行快速
$k $ 近邻搜索。 -
最简单的实现方法:线性扫描。此时要计算输入样本与每个训练样本的距离。
当训练集很大时,计算非常耗时。解决办法是:使用$ kd$ 树来提高
$k $ 近邻搜索的效率。 -
$kd $ 树是一种对$ k$ 维空间中的样本点进行存储以便对其进行快速检索的树型数据结构。它是二叉树,表示对
$k$ 维空间的一个划分。 -
构造$ kd $树的过程相当于不断的用垂直于坐标轴的超平面将 k 维空间切分的过程。
$kd $ 树的每个结点对应于一个$k$ 维超矩形区域。
-
平衡 kd 树构建算法:
-
输入:k 维空间样本集
$\mathbb D={\mathbf {\vec x}_1,\mathbf {\vec x}_2,\cdots,\mathbf {\vec x}_N},\mathbf {\vec x}_i \in \mathcal X \subseteq \mathbb R^{k}$ -
输出:kd 树
-
算法步骤:
-
构造根结点。根结点对应于包含$ \mathbb D$ 的$ k$ 维超矩形。
选择$ x_1
$为轴,以 $ \mathbb D$中所有样本的$ x_1$ 坐标的==中位数==$x_1^* $ 为切分点,将根结点的超矩形切分为两个子区域,切分产生深度为 1 的左、右子结点。切分超平面为:$ x_1=x_1^*$ 。- 左子结点对应于坐标$ x_1<x_1^*$ 的子区域。
- 右子结点对应于坐标
$x_1>x_1^* $ 的子区域。 - 落在切分超平面上的点(
$x_1=x_1^*$ ) 保存在根结点。
-
对深度为$ j$ 的结点,选择$ x_l$ 为切分的坐标轴继续切分,$ l=j\pmod k+1$。本次切分之后,树的深度为
$j+1 $ 。这里取模而不是
$l=j+1 $ ,因为树的深度可以超过维度$k $ 。此时切分轴又重复回到$ x_l$,轮转坐标轴进行切分。 -
直到所有结点的两个子域中没有样本存在时,切分停止。此时形成$ kd$ 树的区域划分。
-
-
-
kd 树最近邻搜索算法( k 近邻搜索以此类推):
-
输入:
- 已构造的
$kd $ 树 - 测试点$ \mathbf {\vec x}$
- 已构造的
-
输出:
$\mathbf {\vec x} $ 的最近邻测试点 -
步骤:
-
初始化:当前最近点为$ \mathbf{\vec x}{nst}=null$,当前最近距离为$ \text{distance}{nst}=\infty $。
-
在 kd 树中找到包含测试点
$\mathbf {\vec x} $ 的叶结点: 从根结点出发,递归向下访问 kd 树(即:执行二叉搜索):- 若测试点$ \mathbf {\vec x} $当前维度的坐标小于切分点的坐标,则查找当前结点的左子结点。
- 若测试点$ \mathbf {\vec x} $当前维度的坐标大于切分点的坐标,则查找当前结点的右子结点。
在访问过程中记录下访问的各结点的顺序,存放在先进后出队列
Queue中,以便于后面的回退。 -
循环,结束条件为
Queue为空。循环步骤为:-
从
Queue中弹出一个结点,设该结点为$ \mathbf{\vec x}_q$。计算 $ \mathbf {\vec x}$到$ \mathbf{\vec x}_q$的距离,假设为 $ \text{distance}_q$ 。若 $\text{distance}q\lt \text{distance}{nst}$,则更新最近点与最近距离:
$\text{distance}_{nst}=\text{distance}q,\quad \mathbf{\vec x}{nst}= \mathbf{\vec x}_q$
-
如果$ \mathbf{\vec x}q$ 为中间节点:考察以$ \mathbf {\vec x} $为球心、以$ \text{distance}{nst}
$为半径的超球体是否与 $ \mathbf{\vec x}_q $所在的超平面相交。如果相交:
- 若
Queue中已经访问过了$ \mathbf{\vec x}_q$的左子树,则继续二叉搜索 $ \mathbf{\vec x}_q $的右子树。 - 若
Queue中已经访问过了$\mathbf{\vec x}_q $ 的右子树,则继续二叉搜索$\mathbf{\vec x}_q $ 的左子树。
二叉搜索的过程中,仍然在
Queue中记录搜索的各结点。 - 若
-
-
循环结束时,$\mathbf{\vec x}_{nst}
$就是 $ \mathbf {\vec x} $的最近邻点。
-
-
-
kd 树搜索的平均计算复杂度为$ O(\log N) $, N 为训练集大小。
kd 树适合$ N >> $k的情形,当 N 与 维度 k 接近时效率会迅速下降。
-
通常最近邻搜索只需要检测几个叶结点即可:
但是如果样本点的分布比较糟糕时,需要几乎遍历所有的结点:
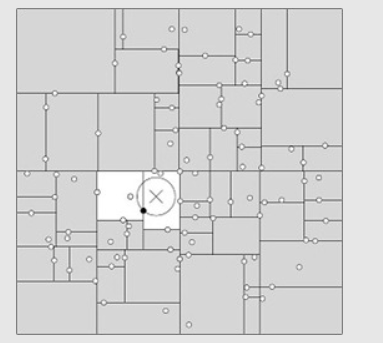
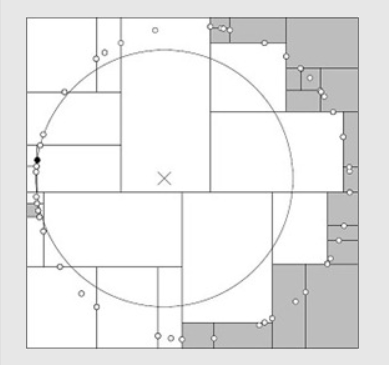
-
假设有 6 个二维数据点:$\mathbb D={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)} $。
构建
kd树的过程:-
首先从
x轴开始划分,根据x轴的取值2,5,9,4,8,7得到中位数为7,因此切分线为:$x=7 $。可以根据
x轴和y轴上数据的方差,选择方差最大的那个轴作为第一轮划分轴。 -
左子空间(记做$ \mathbb D_1$)包含点
(2,3),(5,4),(4,7),切分轴轮转,从y轴开始划分,切分线为:$y=4 $。 -
右子空间(记做
$\mathbb D_2$ )包含点(9,6),(8,1),切分轴轮转,从y轴开始划分,切分线为:y=6 。 -
$\mathbb D_1 $ 的左子空间(记做$ \mathbb D_3$ )包含点(2,3),切分轴轮转,从x轴开始划分,切分线为:x=2。其左子空间记做$ \mathbb D_7$,右子空间记做$ \mathbb D_8
$。由于$ \mathbb D_7,\mathbb D_8$ 都不包含任何点,因此对它们不再继续拆分。 -
$\mathbb D_1 $ 的右子空间(记做$ \mathbb D_4 $)包含点(4,7),切分轴轮转,从x轴开始划分,切分线为:x=4。其左子空间记做
$\mathbb D_9$ ,右子空间记做$\mathbb D_{10} $ 。由于$ \mathbb D_9,\mathbb D_{10}$ 都不包含任何点,因此对它们不再继续拆分。 -
$\mathbb D_2$ 的左子空间(记做$ \mathbb D_5 $)包含点(8,1),切分轴轮转,从x轴开始划分,切分线为:x=8。其左子空间记做
$\mathbb D_{11}$ ,右子空间记做$\mathbb D_{12} $ 。由于$ \mathbb D_{11},\mathbb D_{12}$ 都不包含任何点,因此对它们不再继续拆分。 -
$\mathbb D_2 $ 的右子空间(记做$ \mathbb D_6 $)不包含任何点,停止继续拆分。
-
最终得到样本空间拆分图如下:
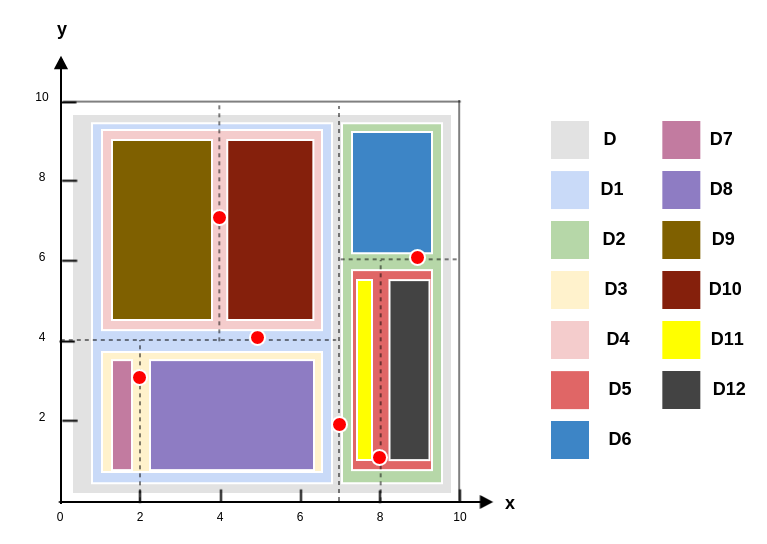
样本空间结构图如下:
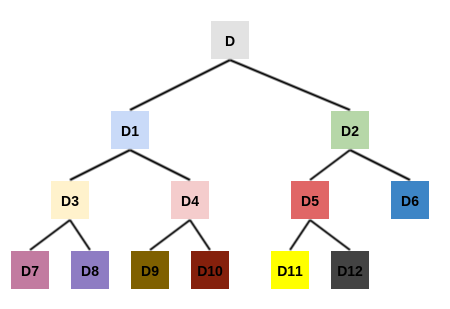
kd 树如下。
kd树以树的形式,根据样本空间的拆分,重新组织了数据集的样本点。每个结点都存放着位于划分平面上数据点。- 由于
样本空间结构图中的叶区域不包含任何数据点,因此叶区域不会被划分。因此kd树的高度要比样本空间结构图的高度少一层。 - 从
kd树中可以清晰的看到坐标轮转拆分。
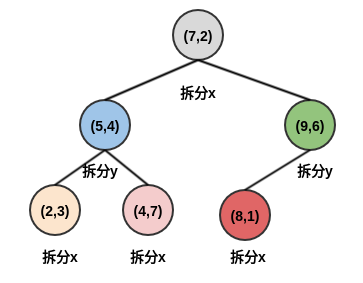
-
假设需要查询的点是
P=(2.1,3.1)。-
首先从
kd树进行二叉查找,最终找到叶子节点(2,3),查找路径为:Queue=<(7,2),(5,4),(2,3)>。 -
Queue弹出结点(2,3):P到(2,3)的距离为0.1414,该距离作为当前最近距离,(2,3)作为候选最近邻点。 -
Queue弹出结点(5,4):P到(5,4)的距离为3.03。候选最近邻点仍然为(2,3),当前最近距离仍然为0.1414。因为结点
(5,4)为中间结点,考察以P为圆心,以0.1414为半径的圆是否与y=4相交。结果不相交,因此不用搜索(5,4)的另一半子树。 -
Queue弹出结点(7,2):P到(7,2)的距离为5.02。候选最近邻点仍然为(2,3),当前最近距离仍然为0.1414。因为结点
(7,2)为中间结点,考察以P为圆心,以0.1414为半径的圆是否与x=7相交。结果不相交,因此不用搜索(7,2)的另一半子树。 -
现在
Queue为空,迭代结束。因此最近邻点为(2,3),最近距离为0.1414。
-
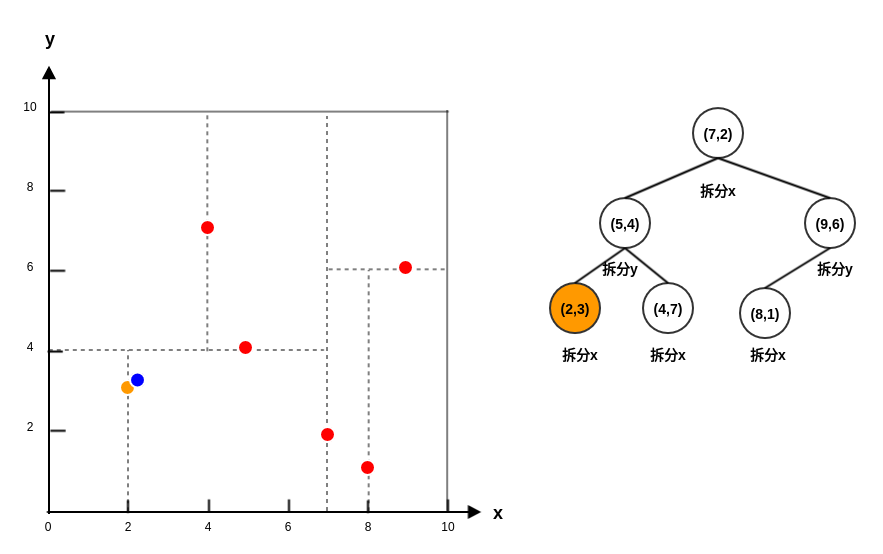
-
假设需要查询的点是
P=(2,4.5)。-
首先从
kd树进行二叉查找,最终找到叶子节点(4,7),查找路径为:Queue=<(7,2),(5,4),(4,7)>。 -
Queue弹出结点(4,7):P到(4,7)的距离为3.202,该距离作为当前最近距离,(4,7)作为候选最近邻点。 -
Queue弹出结点(5,4):P到(5,4)的距离为3.041,该距离作为当前最近距离,(5,4)作为候选最近邻点。因为
(5,4)为中间结点,考察以P为圆心,以3.041为半径的圆是否与y=4相交。结果相交,因此二叉搜索
(5,4)的另一半子树,得到新的查找路径为:Queue=<(7,2),(2,3)>。二叉查找时,理论上
P应该位于结点(5,4)的右子树 。但是这里强制进入(5,4)的左子树,人为打破二叉查找规则。接下来继续维持二叉查找规则。 -
Queue弹出结点(2,3):P到(2,3)的距离为1.5,该距离作为当前最近距离,(2,3)作为候选最近邻点。 -
Queue弹出结点(7,2):P到(7,2)的距离为5.59。候选最近邻点仍然为(2,3),当前最近距离仍然为1.5。因为结点
(7,2)为中间结点,考察以P为圆心,以1.5为半径的圆是否与x=7相交。结果不相交,因此不用搜索(7,2)的另一半子树。 -
现在
Queue为空,迭代结束。因此最近邻点为(2,3),最近距离为1.5。
-
导语:在上一篇《kd 树算法之思路篇》中,我们介绍了如何用二叉树格式记录空间内的距离,并以其为依据进行高效的索引。在本篇文章中,我们将详细介绍 kd 树的构造以及 kd 树上的 kNN 算法。
作者:肖睿
编辑:宏观经济算命师
本文由JoinQuant量化课堂推出,本文的难度属于进阶(下),深度为 level-1
阅读本文前请掌握 kNN(level-1)的知识。
kd树是一个二叉树结构,它的每一个节点记载了【特征坐标,切分轴,指向左枝的指针,指向右枝的指针】。
其中,特征坐标是线性空间中的一个点
。
切分轴由一个整数表示,这里
,是我们在 n 维空间中沿第 r 维进行一次分割。
节点的左枝和右枝分别都是 kd 树,并且满足:如果 y 是左枝的一个特征坐标,那么并且如果 z 是右枝的一个特征坐标,那么
。
给定一个数据样本集 和切分轴 r , 以下递归算法将构建一个基于该数据集的 kd 树,每一次循环制作一个节点:
−− 如果 ,记录 S 中唯一的一个点为当前节点的特征数据,并且不设左枝和右枝。(
指集合 S 中元素的数量)
−− 如果
:
∙∙ 将 S 内所有点按照第 r 个坐标的大小进行排序;
∙∙ 选出该排列后的中位元素(如果一共有偶数个元素,则选择中位左边或右边的元素,左或右并无影响),作为当前节点的特征坐标,并且记录切分轴 r;
∙∙ 将
设为在 S 中所有排列在中位元素之前的元素;
设为在 S 中所有排列在中位元素后的元素;
∙∙ 当前节点的左枝设为以
为数据集并且 r 为切分轴制作出的 kd 树;当前节点的右枝设为以
为数据集并且 r 为切分轴制作出的 kd 树。再设
。(这里,我们想轮流沿着每一个维度进行分割;
是因为一共有 n 个维度,在沿着最后一个维度进行分割之后再重新回到第一个维度。)
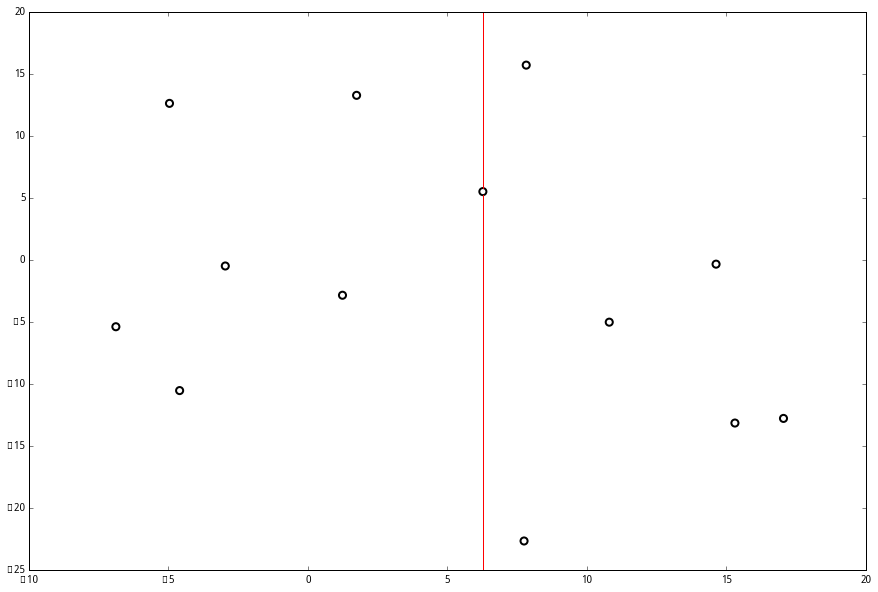
上面抽象的定义和算法确实是很不好理解,举一个例子会清楚很多。首先随机在 中随机生成 13 个点作为我们的数据集。起始的切分轴
;这里
对应 xx 轴,而
对应 y 轴。

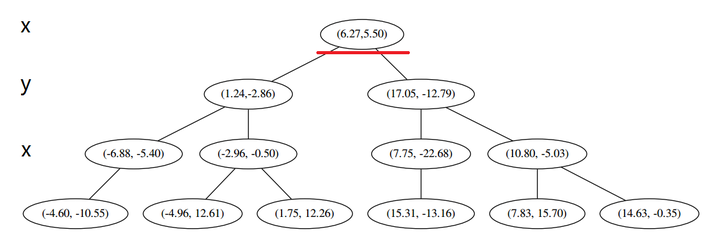
首先先沿 x 坐标进行切分,我们选出 x 坐标的中位点,获取最根部节点的坐标
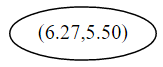
并且按照该点的x坐标将空间进行切分,所有 x 坐标小于 6.27 的数据用于构建左枝,x坐标大于 6.27 的点用于构建右枝。
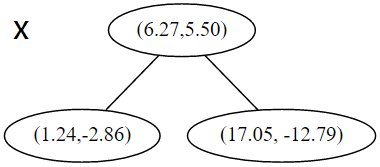
在下一步中 对应 y 轴,左右两边再按照 y 轴的排序进行切分,中位点记载于左右枝的节点。得到下面的树,左边的 x 是指这该层的节点都是沿 x 轴进行分割的。
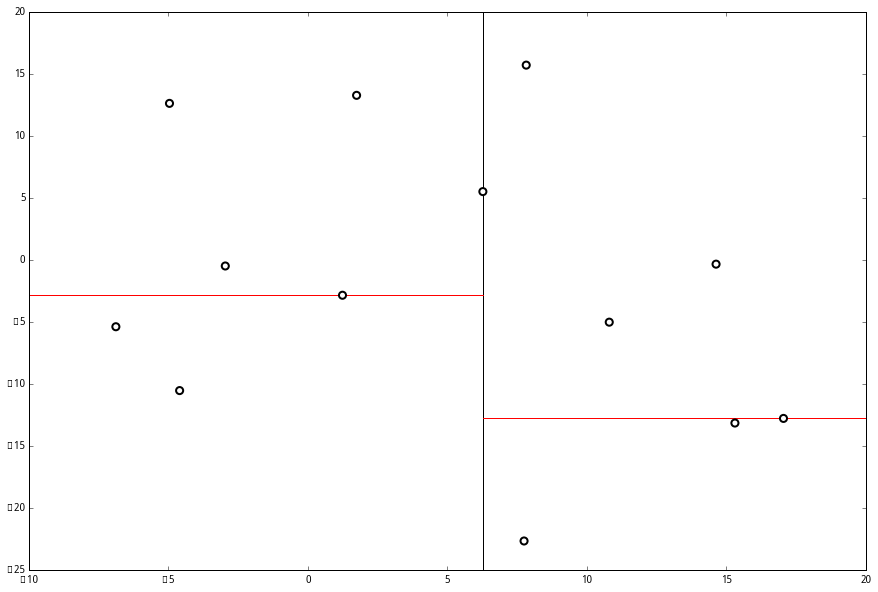
空间的切分如下
下一步中 r≡1+1≡0 mod 2,对应 x 轴,所以下面再按照 x 坐标进行排序和切分,有
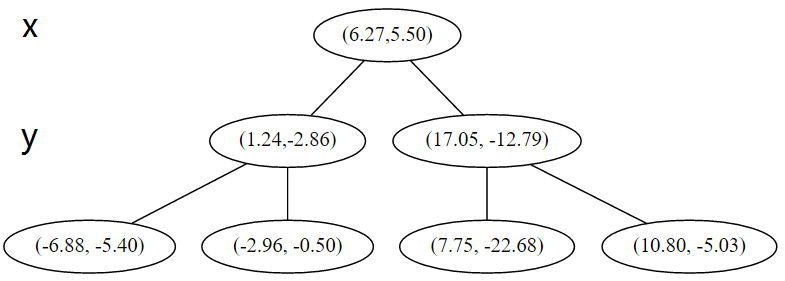
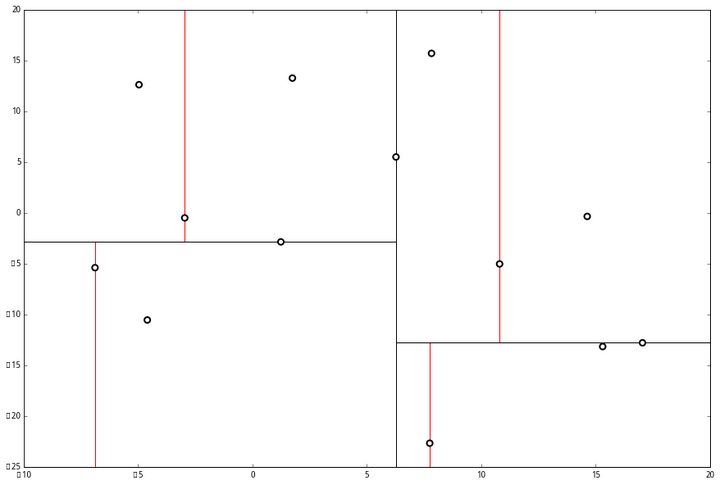
最后每一部分都只剩一个点,将他们记在最底部的节点中。因为不再有未被记录的点,所以不再进行切分。
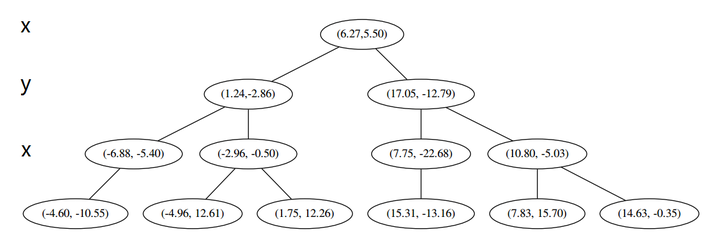
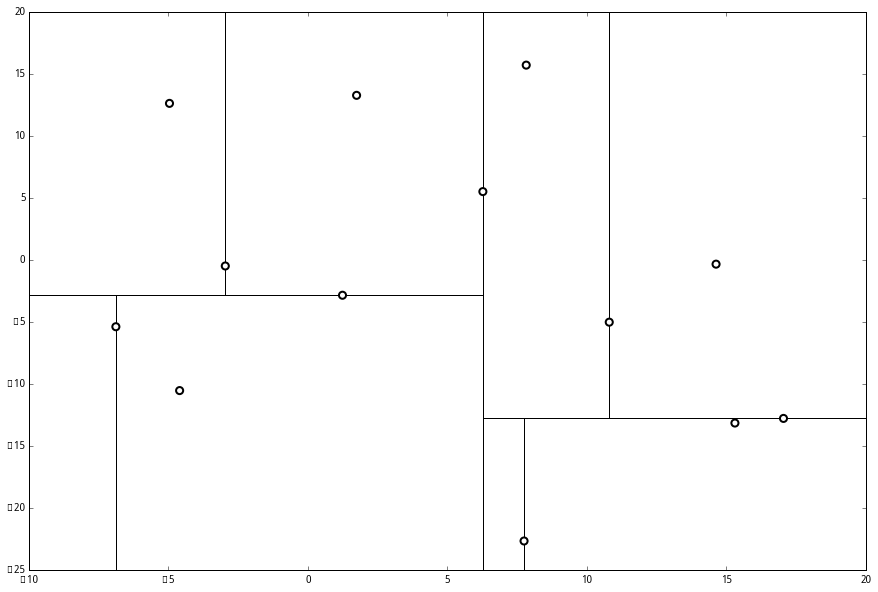
就此完成了 kd 树的构造。
给定一个构建于一个样本集的 kd 树,下面的算法可以寻找距离某个点 p 最近的 k 个样本。
零、设 L 为一个有 k 个空位的列表,用于保存已搜寻到的最近点。
一、根据 p 的坐标值和每个节点的切分向下搜索(也就是说,如果树的节点是照 进行切分,并且 p 的 r 坐标小于 a,则向左枝进行搜索;反之则走右枝)。
二、当达到一个底部节点时,将其标记为访问过。如果 L 里不足 k 个点,则将当前节点的特征坐标加入 L ;如果 L 不为空并且当前节点的特征与 p 的距离小于 L 里最长的距离,则用当前特征替换掉 L 中离 p 最远的点。
三、如果当前节点不是整棵树最顶端节点,执行 (a);反之,输出 L,算法完成。
a. 向上爬一个节点。如果当前(向上爬之后的)节点未曾被访问过,将其标记为被访问过,然后执行 (1) 和 (2);如果当前节点被访问过,再次执行 (a)。
\1. 如果此时 L 里不足 kk 个点,则将节点特征加入 L;如果 L 中已满 k 个点,且当前节点与 p 的距离小于 L 里最长的距离,则用节点特征替换掉 L 中离最远的点。
\2. 计算 p 和当前节点切分线的距离。如果该距离大于等于 L 中距离 p 最远的距离并且 L 中已有 k 个点,则在切分线另一边不会有更近的点,执行 (三);如果该距离小于 L 中最远的距离或者 L 中不足 k 个点,则切分线另一边可能有更近的点,因此在当前节点的另一个枝从 (一) 开始执行。
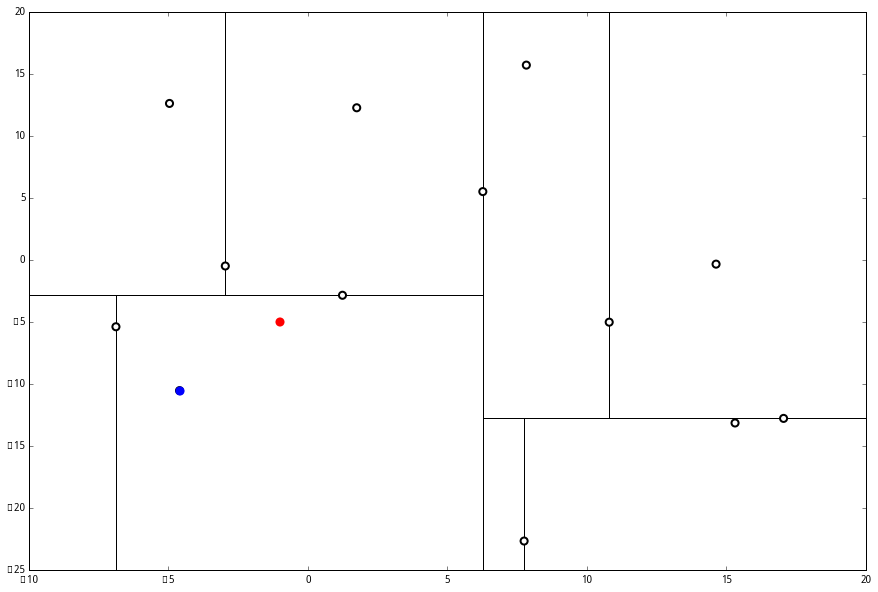
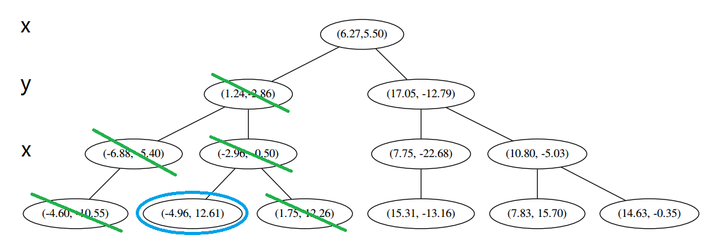
设我们想查询的点为 p=(−1,−5),设距离函数是普通的 距离,我们想找距离问题点最近的 k=3 个点。如下:
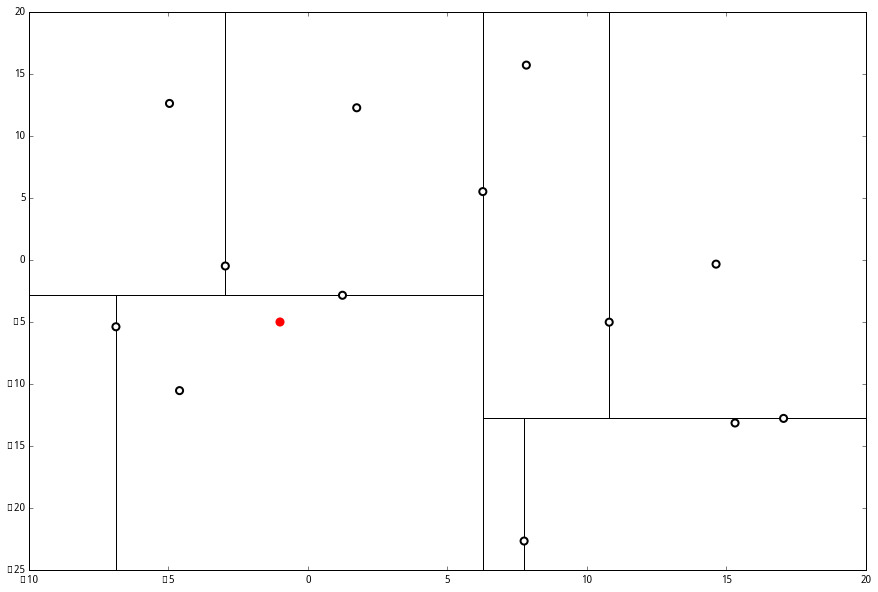
首先执行 (一),我们按照切分找到最底部节点。首先,我们在顶部开始
和这个节点的 x 轴比较一下,
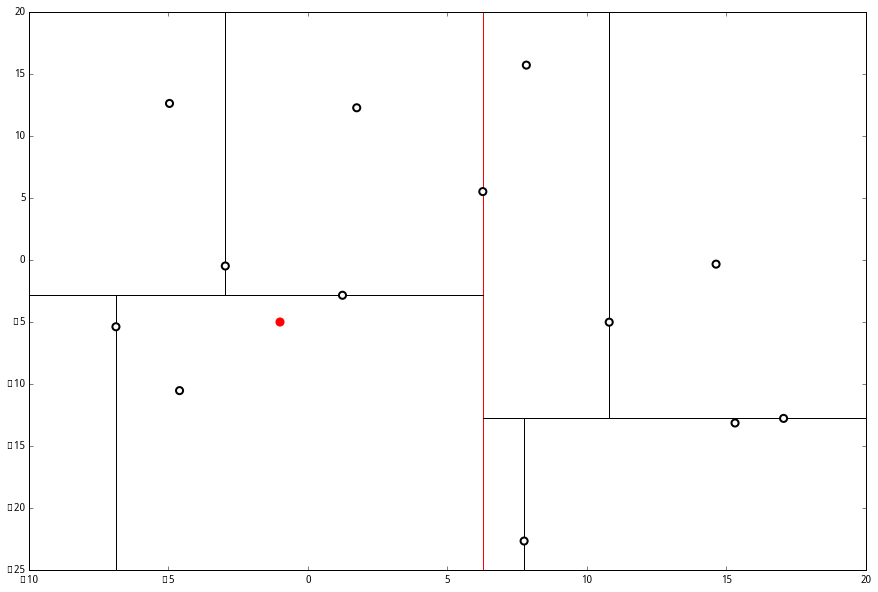
p 的 x 轴更小。因此我们向左枝进行搜索:
这次对比 y 轴,
p 的 y 值更小,因此向左枝进行搜索:
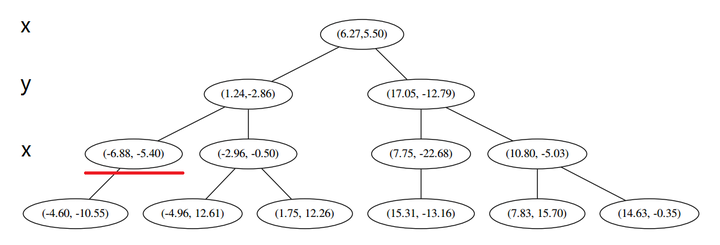
这个节点只有一个子枝,就不需要对比了。由此找到了最底部的节点 (−4.6,−10.55)。
在二维图上是
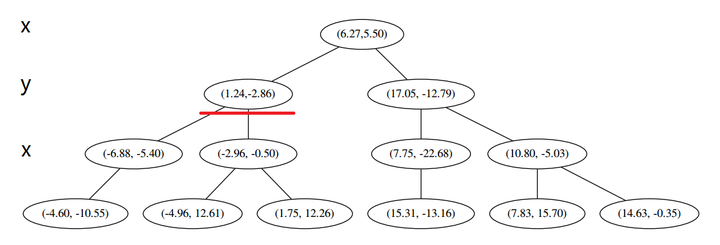
此时我们执行 (二)。将当前结点标记为访问过,并记录下 L=[(−4.6,−10.55)]。啊,访问过的节点就在二叉树上显示为被划掉的好了。
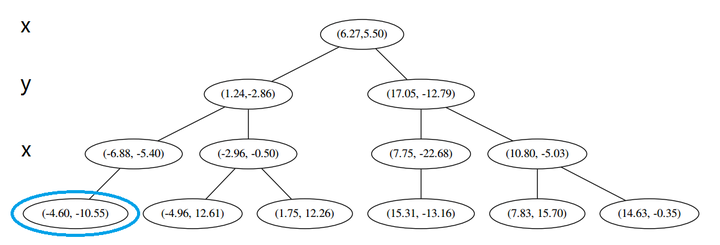
然后执行 (三),嗯,不是最顶端节点。好,执行 (a),我爬。上面的是 (−6.88,−5.4)。
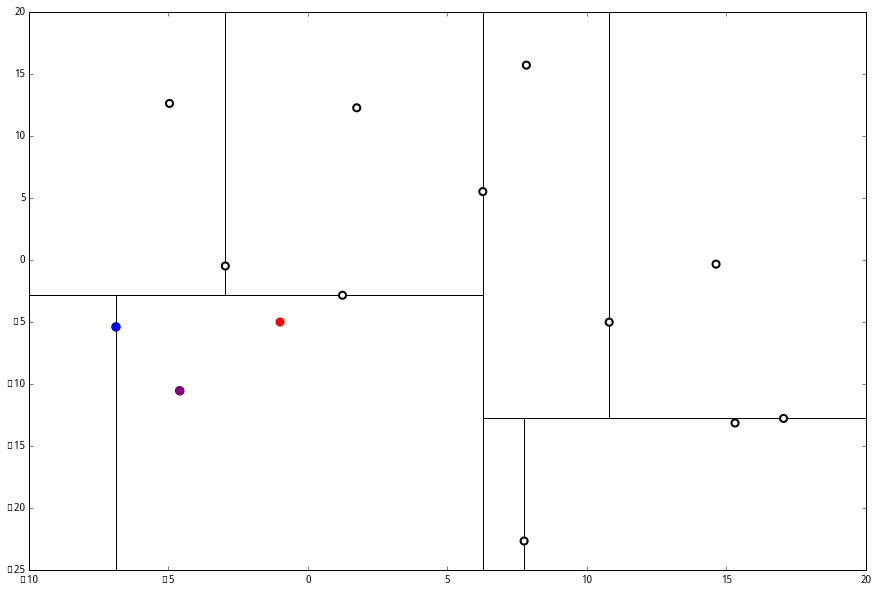
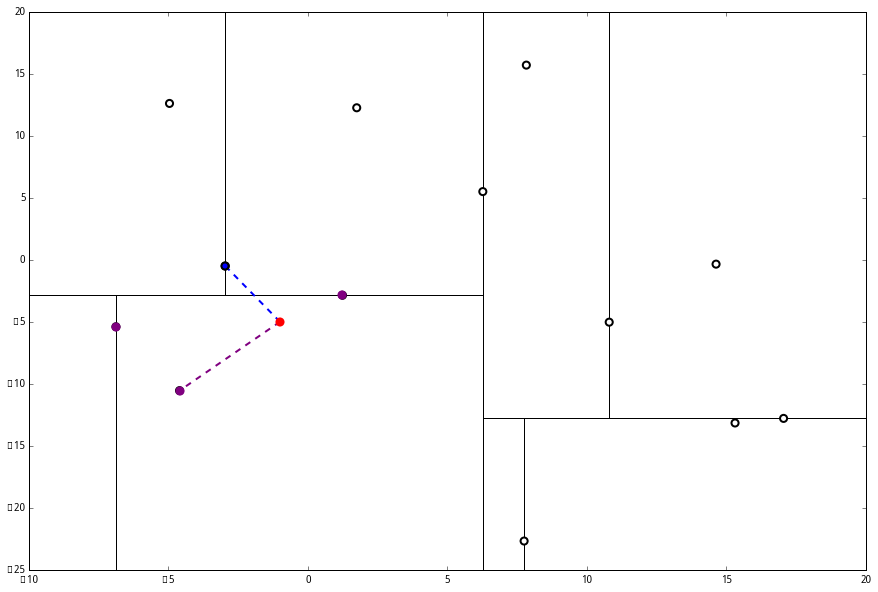
执行 (1),因为我们记录下的点只有一个,小于 k=3,所以也将当前节点记录下,有 L=[(−4.6,−10.55),(−6.88,−5.4)].再执行 (2),因为当前节点的左枝是空的,所以直接跳过,回到步骤 (三)。(三) 看了一眼,好,不是顶部,交给你了,(a)。于是乎 (a) 又往上爬了一节。
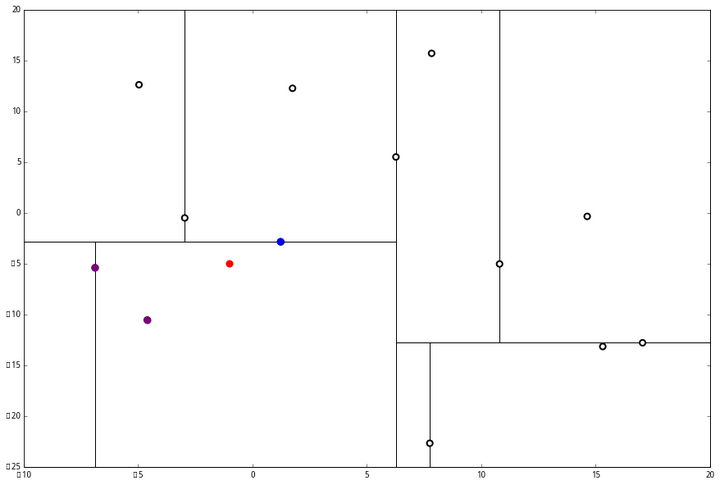
(1) 说,由于还是不够三个点,于是将当前点也记录下,有 L=[(−4.6,−10.55),(−6.88,−5.4),(1.24,−2.86)]。当然,当前结点变为被访问过的。
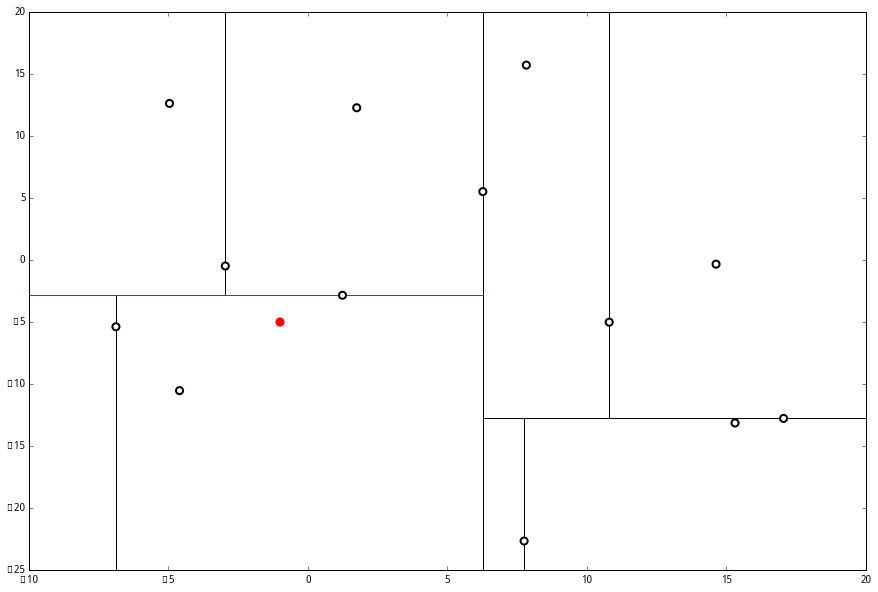
(2) 又发现,当前节点有其他的分枝,并且经计算得出 p 点和 L 中的三个点的距离分别是 6.62,5.89,3.10,但是 p 和当前节点的分割线的距离只有 2.14,小于与 L 的最大距离:
因此,在分割线的另一端可能有更近的点。于是我们在当前结点的另一个分枝从头执行 (一)。好,我们在红线这里:
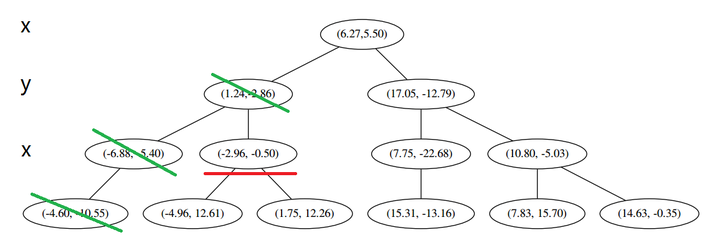
要用 p 和这个节点比较 x 坐标:
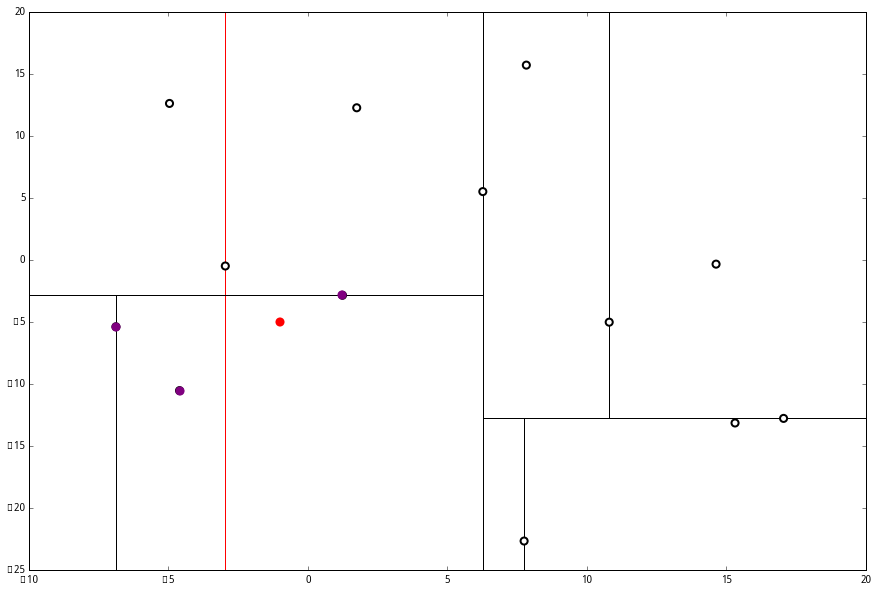
p 的 x 坐标更大,因此探索右枝 (1.75,12.26),并且发现右枝已经是最底部节点,因此启动 (二)。
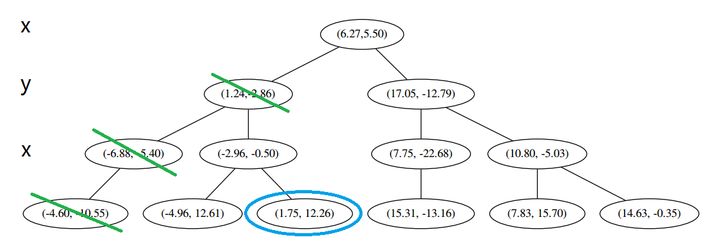
经计算,(1.75,12.26) 与 p 的距离是 17.48,要大于 p 与 L 的距离,因此我们不将其放入记录中。
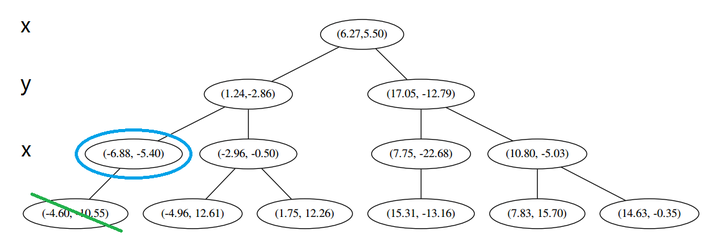
然后 (三) 判断出不是顶端节点,呼出 (a),爬。

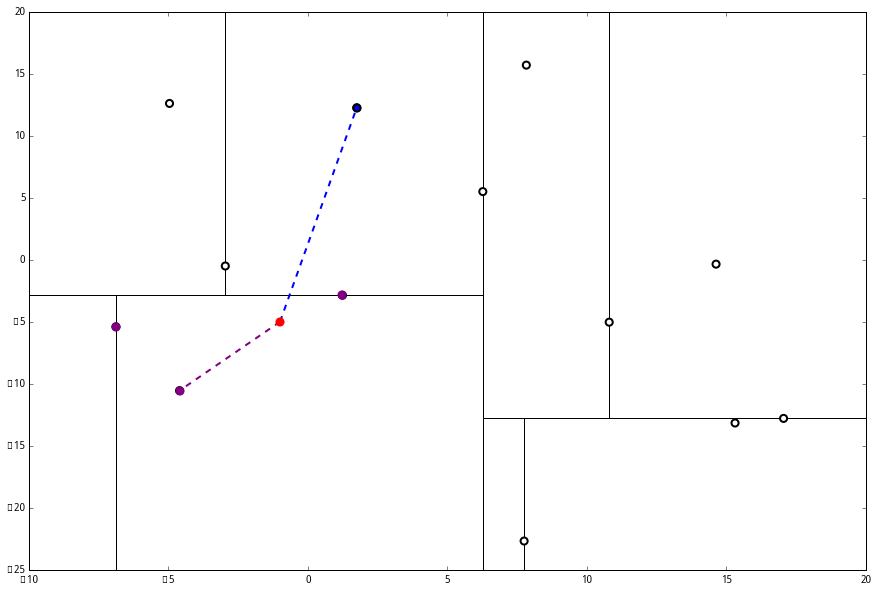
(1) 出来一算,这个节点与 p 的距离是 4.91,要小于 p 与 L 的最大距离 6.62。
因此,我们用这个新的节点替代 L 中离 p 最远的 (−4.6,−10.55)。
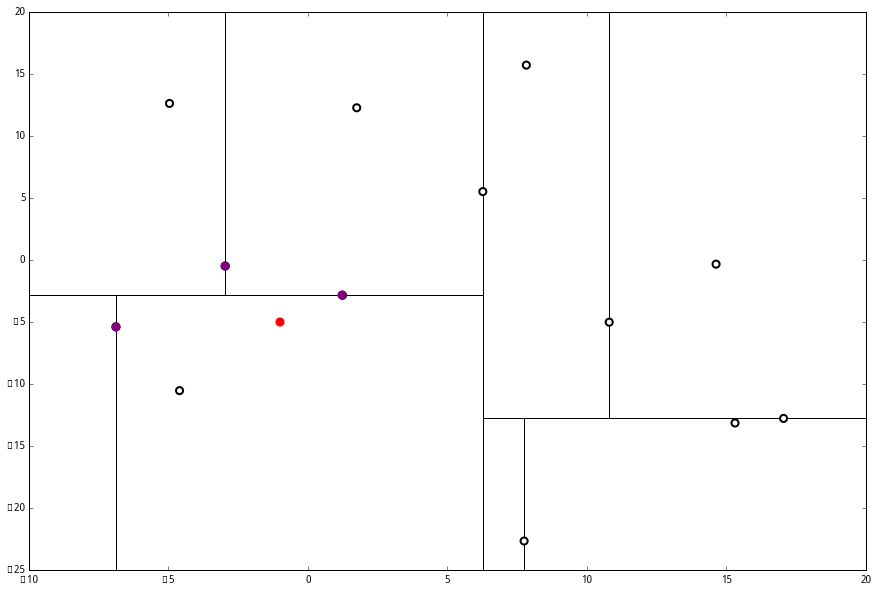
然后 (2) 又来了,我们比对 p 和当前节点的分割线的距离
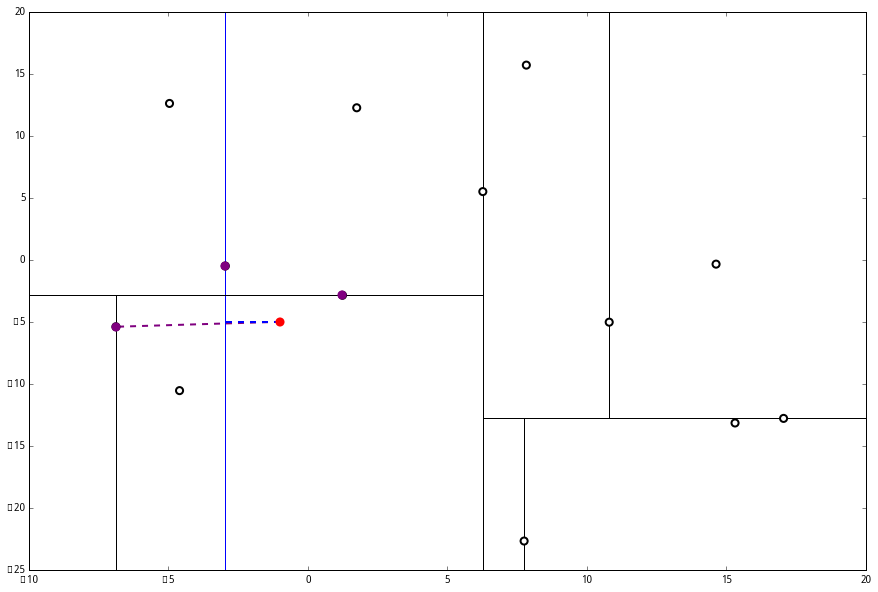
这个距离小于 L 与 p 的最小距离,因此我们要到当前节点的另一个枝执行 (一)。当然,那个枝只有一个点,直接到 (二)。
计算距离发现这个点离 p 比 L 更远,因此不进行替代。
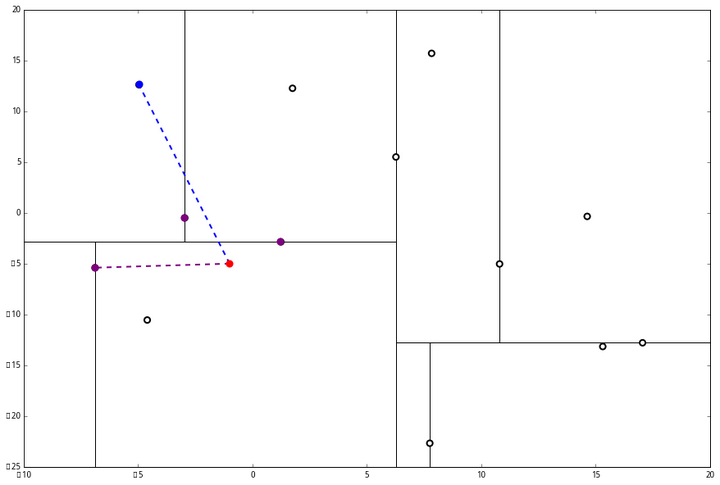
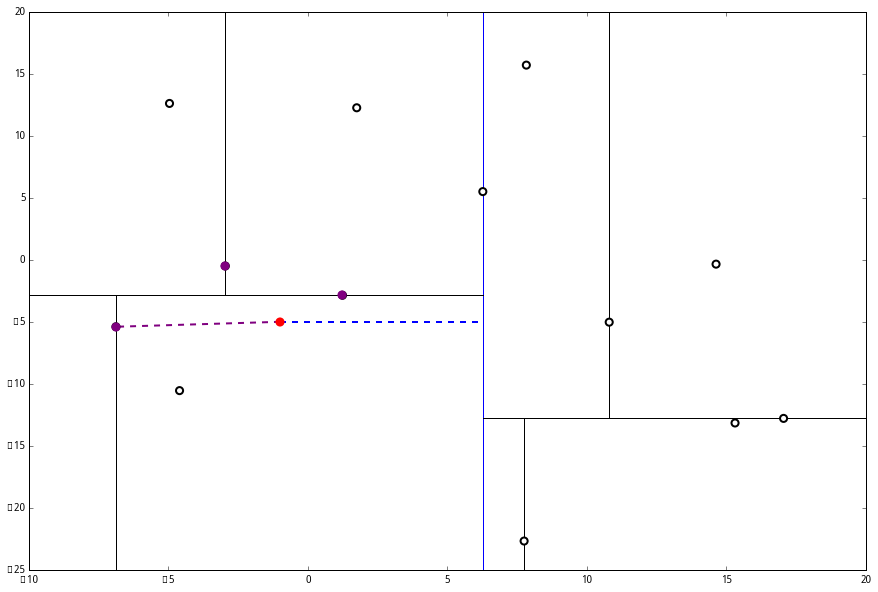
(三) 发现不是顶点,所以呼出 (a)。我们向上爬,
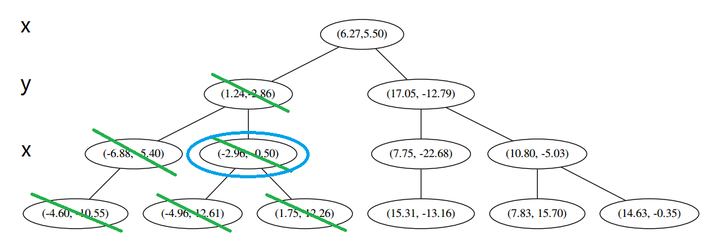
这个是已经访问过的了,所以再来(a),
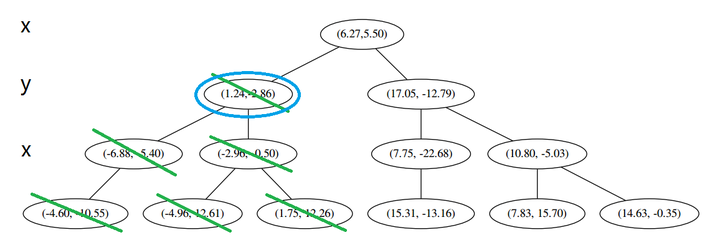
好,(a)再爬,
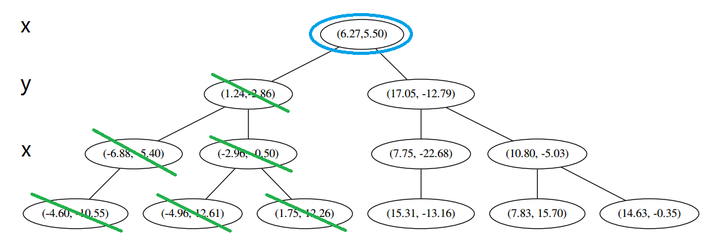
啊!到顶点了。所以完了吗?当然不,还没轮到 (三) 呢。现在是 (1) 的回合。
我们进行计算比对发现顶端节点与p的距离比L还要更远,因此不进行更新。
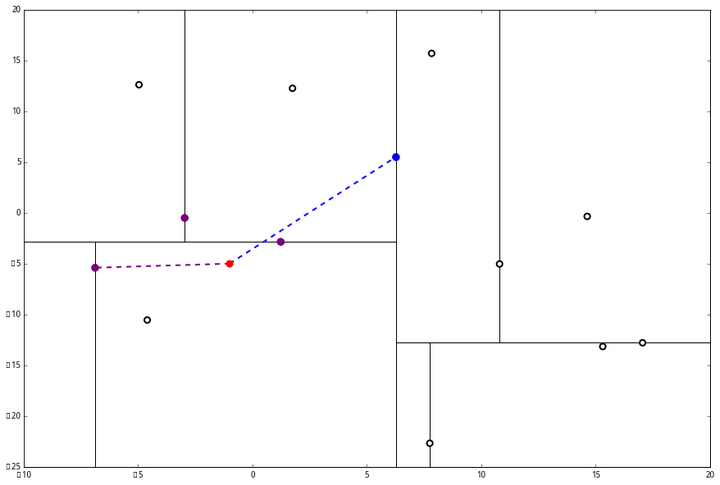
然后是 (2),计算 p 和分割线的距离发现也是更远。
因此也不需要检查另一个分枝。
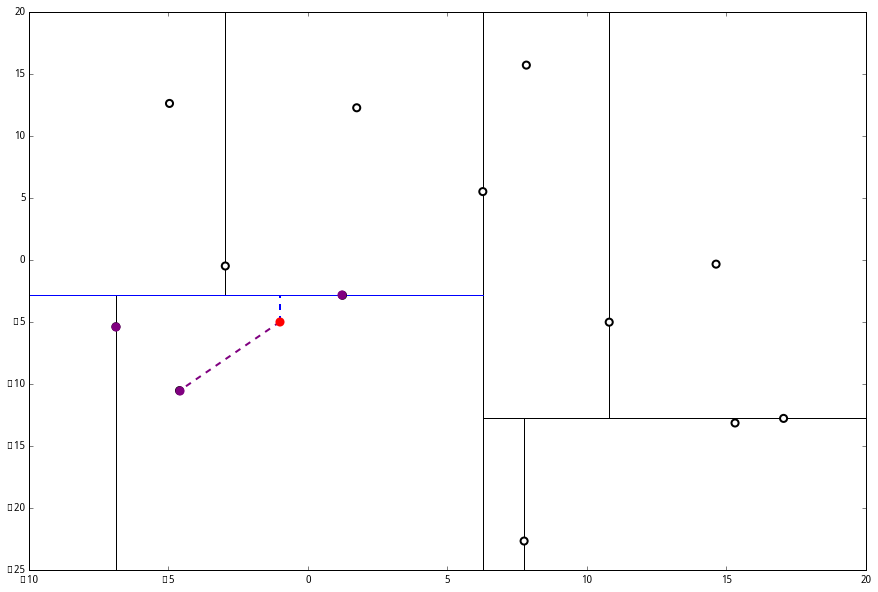
然后执行 (三),判断当前节点是顶点,因此计算完成!输出距离 p 最近的三个样本是 L=[(−6.88,−5.4),(1.24,−2.86),(−2.96,−2.5)]。
kd 树的 kNN 算法节约了很大的计算量(虽然这点在少量数据上很难体现),但在理解上偏于复杂,希望本篇中的实例可以让读者清晰地理解这个算法。喜欢动手的读者可以尝试自己用代码实现 kd 树算法,但也可以用现成的机器学习包 scikit-learn 来进行计算。