 +
+
+## Setting up the doodle front-end
+### Lauch the app
+To simplify this tutorial we will only be running the front-end of the application, which can be launched by using these commands:
+
+
+## Setting up the doodle front-end
+### Lauch the app
+To simplify this tutorial we will only be running the front-end of the application, which can be launched by using these commands:




 +
+### Targetting Attributes
+The first setting that matters is the "assign value based on attribute". Every user has a set of attribute that is associated to them, I kept those provided by default but they can be changed in "Features>Attributes".
+
+### Targetting Attributes
+The first setting that matters is the "assign value based on attribute". Every user has a set of attribute that is associated to them, I kept those provided by default but they can be changed in "Features>Attributes". +
+## Analysis
+Growthbook also allows for analysis about the different experiments, to do that you can connect a datasource to it and define metrics that helps you compare the versions of your apps. For example for our centered title we could mesure the time on site or the bounce rate which would give us an insight on what the users think about the feature.
+
diff --git a/CanaryTesting.md b/CanaryTesting.md
new file mode 100644
index 00000000..eed9e9ca
--- /dev/null
+++ b/CanaryTesting.md
@@ -0,0 +1,47 @@
+# Canary Testing
+
+## Introduction
+
+Canary testing is a method of software verification whose principle is to deploy a new version of the application to a subset of users. It allows to test the application in a real situation while not affecting all the population using it, and in case of failure, affects less users.
+
+For example, Meta uses the Canary Testing method on its employess applications and then can gather information quickly by gathering data and feedback from the employees without affecting the external users.
+
+Canary testing and A/B testing are similar in deployment, but their objective is different. Canary testing is meant to test resilience of new features, while A/B testing is meant to gather feedback on user experience between multiple already working features.
+
+Like A/B testing, the Canary method fits well with continous software deployment.
+
+## Implementation
+
+Canary and A/B testing being similar, we can then use the same tutorial than for [A/B testing](./ABTesting.md).
+
+However, due to the difference in the objectives of both methods, we have to modify certain parameters. The first parameter is the population. We do not want to have a large part of the user base (for example 50% like in the A/B tutorial), so we can have different methods of user separation :
+ - Employees separation
+ - 90/10 ratio (or less depending on the magnitude of the changes or risks, going as low as 99/1), 10 being the percentage of the population getting the new features to test.
+
+### Employees separation
+
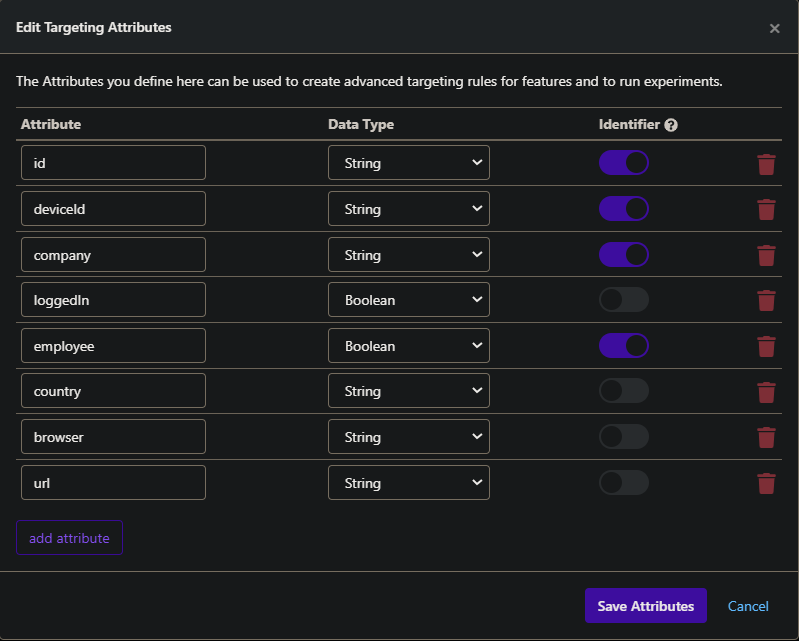
+After the feature creation in your Growthbook, instead of selecting A/B Experiment, we will have to go to "Features>Attributes" and then click on "Edit Attributes" on the top right corner.
+
+
+
+You then need to tick the "Identifier" column corresponding to the "employee" attribute, like shown in the image above. This will allow you to select "employee" as a separation factor later.
+
+To do that, go to "Features>All Features" and select the feature created before. Like in the A/B testing tutorial, select **A/B Experiment** in the "Override Rules" section.
+
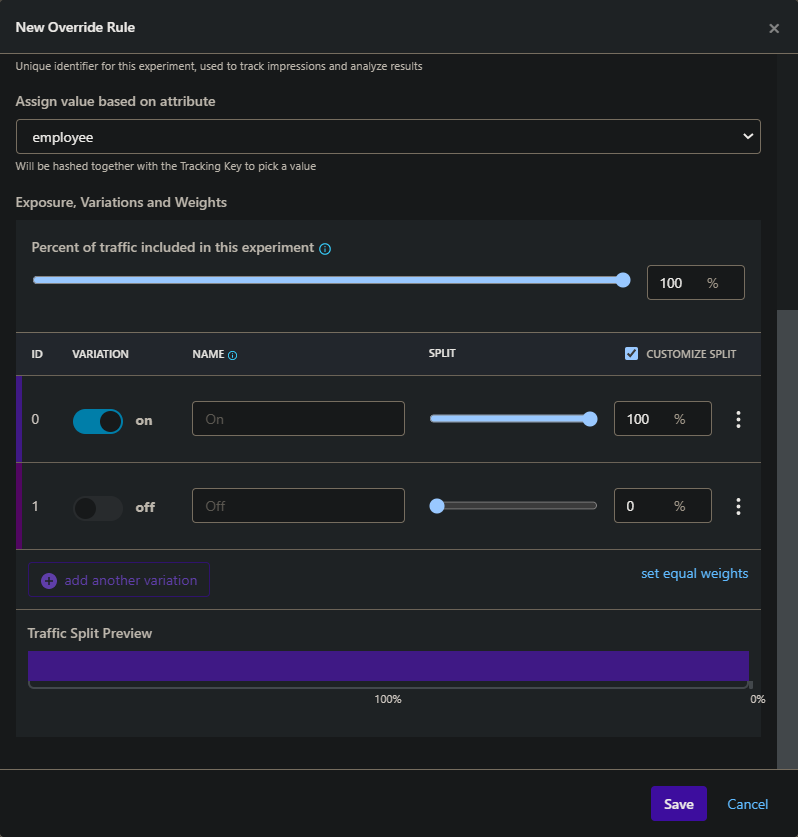
+Instead of keeping the id in "Assign value based on attribute", you are now able to select "employee". Tick "Customize Split" in the "Exposure, Variations and Weight" section and bring the slider bar to 100% for the "On" option. This activates the option "On" for every employee, but no other user.
+
+
+
+
+### 99/1
+
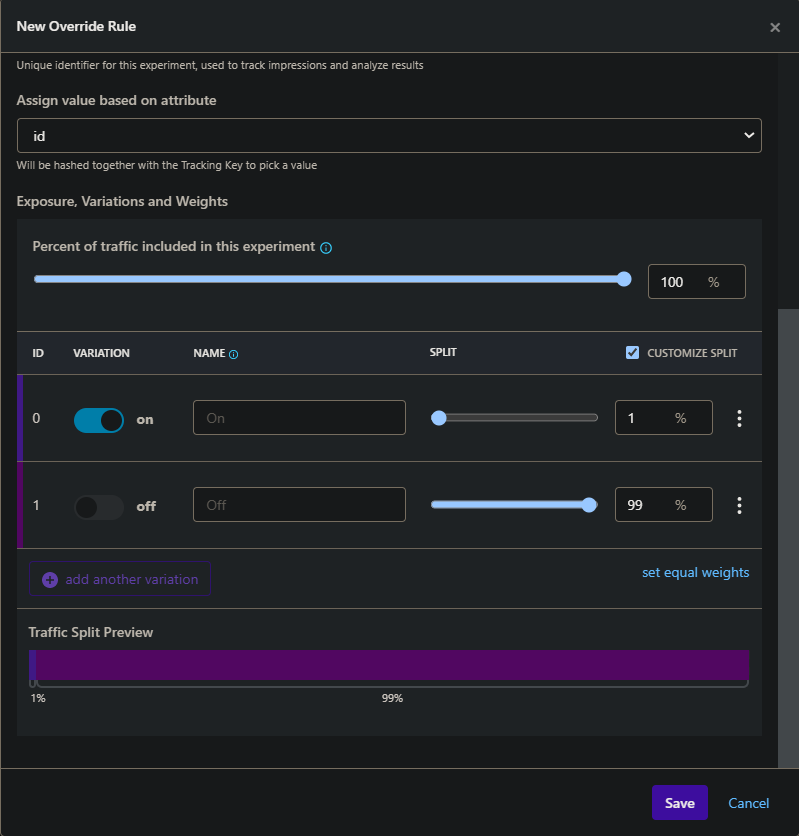
+If you want to test your application with a certain percentage of the user population, you then need to use "id" instead of "employee" in your override rule, and then bring the slider to 1% for the "On" option instead of 100%. Only 1% of users will then have the new features.
+
+
+
+You are now able to change different separation rules based on your testing strategy !
+
+### Logging
+
+For the Canary testing method to work fully, you have to be able to detect errors within the population using the new features. For that, you need to be sure that your logging process is functionning well and easy for the users to use.
+If the test users are the employees, error reporting can even be easier because they will be able to quickly report and describe the errors.
diff --git a/Fuzzing.md b/Fuzzing.md
new file mode 100644
index 00000000..30923d99
--- /dev/null
+++ b/Fuzzing.md
@@ -0,0 +1,122 @@
+# Fuzzing
+## Introduction
+Fuzzing is a way of testing applications by providing random data as input trying to trigger errors such as exceptions, memory leak, stack smashing, double free or even higer level flaws such as sql injection.
+
+Fuzzing can be applied to various type of systems : API, binaries, web apps..
+
+Fuzzing is primarily used in two fields : V&V and Security
+Depending on the objectives the data generation techniques vary :
+- Grammar
+- Dictionnary
+- random mutators
+
+## Fuzzing Doodle
+
+Doodle is an application with multiple surface attack.
+We could choose to fuzz :
+- The API
+- The back-end binaries
+
+## Fuzz the API
+
+### Using Burp Suite
+Burp Suite is a paid software with a free limited version. Its purpose is to do penetration testing of web application. The intruder feature enables us to fuzz our Doodle API.
+
+After downloading Burp, you can open it and create a new project or a temporary project :
+
+
+## Analysis
+Growthbook also allows for analysis about the different experiments, to do that you can connect a datasource to it and define metrics that helps you compare the versions of your apps. For example for our centered title we could mesure the time on site or the bounce rate which would give us an insight on what the users think about the feature.
+
diff --git a/CanaryTesting.md b/CanaryTesting.md
new file mode 100644
index 00000000..eed9e9ca
--- /dev/null
+++ b/CanaryTesting.md
@@ -0,0 +1,47 @@
+# Canary Testing
+
+## Introduction
+
+Canary testing is a method of software verification whose principle is to deploy a new version of the application to a subset of users. It allows to test the application in a real situation while not affecting all the population using it, and in case of failure, affects less users.
+
+For example, Meta uses the Canary Testing method on its employess applications and then can gather information quickly by gathering data and feedback from the employees without affecting the external users.
+
+Canary testing and A/B testing are similar in deployment, but their objective is different. Canary testing is meant to test resilience of new features, while A/B testing is meant to gather feedback on user experience between multiple already working features.
+
+Like A/B testing, the Canary method fits well with continous software deployment.
+
+## Implementation
+
+Canary and A/B testing being similar, we can then use the same tutorial than for [A/B testing](./ABTesting.md).
+
+However, due to the difference in the objectives of both methods, we have to modify certain parameters. The first parameter is the population. We do not want to have a large part of the user base (for example 50% like in the A/B tutorial), so we can have different methods of user separation :
+ - Employees separation
+ - 90/10 ratio (or less depending on the magnitude of the changes or risks, going as low as 99/1), 10 being the percentage of the population getting the new features to test.
+
+### Employees separation
+
+After the feature creation in your Growthbook, instead of selecting A/B Experiment, we will have to go to "Features>Attributes" and then click on "Edit Attributes" on the top right corner.
+
+
+
+You then need to tick the "Identifier" column corresponding to the "employee" attribute, like shown in the image above. This will allow you to select "employee" as a separation factor later.
+
+To do that, go to "Features>All Features" and select the feature created before. Like in the A/B testing tutorial, select **A/B Experiment** in the "Override Rules" section.
+
+Instead of keeping the id in "Assign value based on attribute", you are now able to select "employee". Tick "Customize Split" in the "Exposure, Variations and Weight" section and bring the slider bar to 100% for the "On" option. This activates the option "On" for every employee, but no other user.
+
+
+
+
+### 99/1
+
+If you want to test your application with a certain percentage of the user population, you then need to use "id" instead of "employee" in your override rule, and then bring the slider to 1% for the "On" option instead of 100%. Only 1% of users will then have the new features.
+
+
+
+You are now able to change different separation rules based on your testing strategy !
+
+### Logging
+
+For the Canary testing method to work fully, you have to be able to detect errors within the population using the new features. For that, you need to be sure that your logging process is functionning well and easy for the users to use.
+If the test users are the employees, error reporting can even be easier because they will be able to quickly report and describe the errors.
diff --git a/Fuzzing.md b/Fuzzing.md
new file mode 100644
index 00000000..30923d99
--- /dev/null
+++ b/Fuzzing.md
@@ -0,0 +1,122 @@
+# Fuzzing
+## Introduction
+Fuzzing is a way of testing applications by providing random data as input trying to trigger errors such as exceptions, memory leak, stack smashing, double free or even higer level flaws such as sql injection.
+
+Fuzzing can be applied to various type of systems : API, binaries, web apps..
+
+Fuzzing is primarily used in two fields : V&V and Security
+Depending on the objectives the data generation techniques vary :
+- Grammar
+- Dictionnary
+- random mutators
+
+## Fuzzing Doodle
+
+Doodle is an application with multiple surface attack.
+We could choose to fuzz :
+- The API
+- The back-end binaries
+
+## Fuzz the API
+
+### Using Burp Suite
+Burp Suite is a paid software with a free limited version. Its purpose is to do penetration testing of web application. The intruder feature enables us to fuzz our Doodle API.
+
+After downloading Burp, you can open it and create a new project or a temporary project :
+ +
+
+Choose default settings :
+
+
+
+Choose default settings :
+ +
+
+Go to the "Intruder" tab and set up the HTTP request and choose what variable you will fuzz :
+
+
+
+Go to the "Intruder" tab and set up the HTTP request and choose what variable you will fuzz :
+ +
+
+Then in the Payload tab choose how to generate data :
+
+
+
+Then in the Payload tab choose how to generate data :
+ +
+
+You can now launch the "attack" and check the server response.
+You can use this tool to either check if your API works as intended, or, to try find bugs.
+
+### Using a custom script (Python)
+If no off the shelf software meet your needs, you can easily build custom script to fuzz your API
+```python
+import requests
+import random
+import string
+
+NUMBER_OF_TRY = 100
+
+def get_random_string(length):
+ # choose from all lowercase letter
+ letters = string.hexdigits
+ result_str = ''.join(random.choice(letters) for i in range(length))
+ return result_str
+
+# Define the URL of the API you want to fuzz
+api_url = "http://localhost:4200/api/pool/slug/"
+
+
+# Define a list of input values to use for fuzzing the API
+fuzz_values = [get_random_string(24) for i in range(NUMBER_OF_TRY)]
+
+
+# Iterate over the list of fuzz values and make a request to the API for each value
+for val in fuzz_values:
+ # Make a GET request to the API using the current fuzz value as a query parameter
+ response = requests.get(api_url, params={"fuzz_param": val})
+
+ # Print the status code of the response
+ print(f"Response for fuzz value {val}: {response.status_code}")
+```
+
+this script is calling the API trying to find hidden pool.
+
+```
+Response for fuzz value 538BEB050aAbEE2E788eB988: 404
+Response for fuzz value FCb2eCd5175F8E69fcd3dcF4: 404
+Response for fuzz value eA47ecbd2eBe57393Eb7b2D7: 404
+Response for fuzz value 2f0b85c6A83094bEa1b47aBa: 404
+Response for fuzz value 1f83332CD7fDBBFC74c7d596: 404
+Response for fuzz value 4F63a34CbeBDAdD89bE15cc2: 404
+Response for fuzz value 6D53D03a1F2Db4B330Afd72E: 404
+Response for fuzz value 57D7bdAb1FFE4a45eF7Ba7Cb: 404
+Response for fuzz value B73b0F2B6Bd3Cb844FD77C40: 404
+Response for fuzz value c03fEBaAd2E84F2FEDDbEA6F: 404
+Response for fuzz value 0eC0EA9Fd8F802DdbB4C32eF: 404
+Response for fuzz value 7cEC2eBA2c8CaA7e450Bf633: 404
+Response for fuzz value 4DB83db2ed15D5da820fCeA0: 404
+Response for fuzz value CA2C4999d1fE4eF654fbA763: 404
+Response for fuzz value 9fE25DfFDFaFf23f5b4269D8: 404
+```
+
+This is a fraction of the result we get. Since we did not find any hidden pool we receive 404 errors.
+
+## Fuzz the backend binary
+
+To fuzz our backend, we will use Jazzer. Jazzer is a fuzzer working with JVMs. The fuzzer will try to cover as much code as possible by using JVMs features to know what is the code coverage acheived by each input data.
+The basic usage is to use the autofuzz fonctionality and let Jazzer decide what input and what mutators to use.
+
+In the case of doodle we have not to forget to lauch the etherpad and database dockers.
+
+```./jazzer --cp=./tlcdemoApp-1.0.0-SNAPSHOT.jar --autofuzz=org.apache.commons.imaging.Imaging::getBufferedImage```
+
+if jazzer find a bug it will save the raw input in a file and also a java code to reproduce the crash and easily turn it into a junit test case.
+
+
+
+You can now launch the "attack" and check the server response.
+You can use this tool to either check if your API works as intended, or, to try find bugs.
+
+### Using a custom script (Python)
+If no off the shelf software meet your needs, you can easily build custom script to fuzz your API
+```python
+import requests
+import random
+import string
+
+NUMBER_OF_TRY = 100
+
+def get_random_string(length):
+ # choose from all lowercase letter
+ letters = string.hexdigits
+ result_str = ''.join(random.choice(letters) for i in range(length))
+ return result_str
+
+# Define the URL of the API you want to fuzz
+api_url = "http://localhost:4200/api/pool/slug/"
+
+
+# Define a list of input values to use for fuzzing the API
+fuzz_values = [get_random_string(24) for i in range(NUMBER_OF_TRY)]
+
+
+# Iterate over the list of fuzz values and make a request to the API for each value
+for val in fuzz_values:
+ # Make a GET request to the API using the current fuzz value as a query parameter
+ response = requests.get(api_url, params={"fuzz_param": val})
+
+ # Print the status code of the response
+ print(f"Response for fuzz value {val}: {response.status_code}")
+```
+
+this script is calling the API trying to find hidden pool.
+
+```
+Response for fuzz value 538BEB050aAbEE2E788eB988: 404
+Response for fuzz value FCb2eCd5175F8E69fcd3dcF4: 404
+Response for fuzz value eA47ecbd2eBe57393Eb7b2D7: 404
+Response for fuzz value 2f0b85c6A83094bEa1b47aBa: 404
+Response for fuzz value 1f83332CD7fDBBFC74c7d596: 404
+Response for fuzz value 4F63a34CbeBDAdD89bE15cc2: 404
+Response for fuzz value 6D53D03a1F2Db4B330Afd72E: 404
+Response for fuzz value 57D7bdAb1FFE4a45eF7Ba7Cb: 404
+Response for fuzz value B73b0F2B6Bd3Cb844FD77C40: 404
+Response for fuzz value c03fEBaAd2E84F2FEDDbEA6F: 404
+Response for fuzz value 0eC0EA9Fd8F802DdbB4C32eF: 404
+Response for fuzz value 7cEC2eBA2c8CaA7e450Bf633: 404
+Response for fuzz value 4DB83db2ed15D5da820fCeA0: 404
+Response for fuzz value CA2C4999d1fE4eF654fbA763: 404
+Response for fuzz value 9fE25DfFDFaFf23f5b4269D8: 404
+```
+
+This is a fraction of the result we get. Since we did not find any hidden pool we receive 404 errors.
+
+## Fuzz the backend binary
+
+To fuzz our backend, we will use Jazzer. Jazzer is a fuzzer working with JVMs. The fuzzer will try to cover as much code as possible by using JVMs features to know what is the code coverage acheived by each input data.
+The basic usage is to use the autofuzz fonctionality and let Jazzer decide what input and what mutators to use.
+
+In the case of doodle we have not to forget to lauch the etherpad and database dockers.
+
+```./jazzer --cp=./tlcdemoApp-1.0.0-SNAPSHOT.jar --autofuzz=org.apache.commons.imaging.Imaging::getBufferedImage```
+
+if jazzer find a bug it will save the raw input in a file and also a java code to reproduce the crash and easily turn it into a junit test case.
+ +
+And the generated java code :
+```java
+public class Crash_adc83b19e793491b1c6ea0fd8b46cd9f32e592fc {
+ public static void main(String[] args) throws Throwable {
+ (((java.util.function.Supplier
+
+And the generated java code :
+```java
+public class Crash_adc83b19e793491b1c6ea0fd8b46cd9f32e592fc {
+ public static void main(String[] args) throws Throwable {
+ (((java.util.function.Supplier