Here we explain some technical terms about reinforcement learning algorithms and related terminology. More definitions and explanations will be added as we advance in our research.
An episode is one iteration of our game, it is divided in Steps. Once our agent loses all its lifes, it prints the rewards obtained and the game resets. To train our agent we need to let it run over multiple episodes.
A step or movement is one single action taken by our agent, for example, moving to the right. This actions are randomly chosen on the exploration phase and decided based on past actions in the exploitation phase.
An action is an specific movement that can be performed on a step, in each enviroment or game they are a finite range of actions that can be taken, for example: moving left, right, up, down, shoot and do nothing could be a set of actions. Our algorithm has to select one action from this set on each step based on experience or randomness.
The action space is the collection of possible actions for a certain enviroment.
A reward is a numeric value that represents the gains obtained by a certain action in our enviroment, they are used to tell our algorithms what actions are worth and how much they are worth to solve the enviroment. Its fundamental to give rewards when the step chosen led to improvements and to take back rewards if the step chosen led to a bad result.
Neural networks use weights to calibrate each neuron in each layer, the training process consists in finding the best weights for each individual neuron to obtain the best ouput at the final layer based on the input given. This weights can be saved into a file to retain the state of the model and can be load later to bring back that state.
The less effort result we have to beat, for example, if a random set of movements can produce a score of 100, then 100 is the baseline to beat.
As we are producing outputs based on a predefined algorithm we want to set the random values to a certain value to make our results predictable and deterministic. This way, if other researchers want they can obtain the same results in each of the runs of the algorithm by setting the same seed. This seed can and should be fixed at the beginning of our program by invoking random.seed().
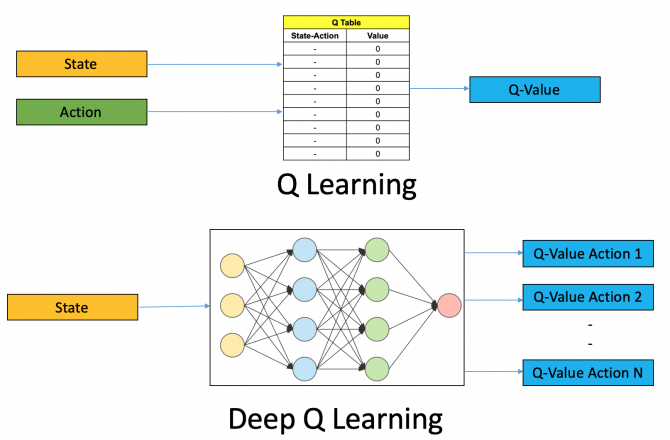
Deep reinforcement learning instead uses a neural network to approximate the Q-function.
Decision-making function, accepts a state as input and “decides” on an action. policy: state -> action
Step 1. Create Q-table, all zeroes Step 2. Choose an action Step 3. Perform an action Step 4. Measure the reward Step 5. Update the Q-table
A simple lookup table where we calculate the maximum expected future rewards for action at each state. This table will guide us to the best action at each state.
state action reward state0 shoot 10 state0 right 3 state0 left 3
A Q-table is not sustainable as games are increasingly complex. For this reason, we need a way to approximate the Q-table, as most games have too many states to list in the table. In that cases, the Q-learning agent learns a Q-function instead of a Q-table.
Q(state, action) = reward
It is a value that ranges from 1 to 0, when its near 1, our algorithm will be in the explotation phase, that means that it will try random movements. When its near 0, our algorithm will be in an exploration phase, it will try the movements from its memory that have a higher confidence. In each step, the algorithm chooses to perform a random or predefined movement depending on the epsilon value, that decays through time.
The replay memory, replay buffer or experience replay are terms that refer to a technique that allows the agent to learn from earlier memories, this can speed up learning and break undesirable temporal correlations. [1]
When using Keras, the model architecture and model weights are clearly separated [3]. In our project, the model architecture is defined in the Deep_Q.py and Duel_Q.py files, when constructing the layers.
On the opposite, Model Weights have to be saved to make our state persist between launches, thats when the HDF5 format comes handy. Its a grid format that keras uses to store multi-dimensional arrays filled with numbers, the weights of our neurons.
You can find them in openai-pacman/results/, the file extension is .h5 and they are not supposed to be open with a text editor, you need to use tools like HDFView [4].

[1] https://www.padl.ws/papers/Paper%2018.pdf
[2] https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/
[3] https://machinelearningmastery.com/save-load-keras-deep-learning-models/
[4] https://www.hdfgroup.org/downloads/hdfview/
https://junedmunshi.wordpress.com/2012/03/30/how-to-implement-epsilon-greedy-strategy-policy/
https://medium.com/@dennybritz/exploration-vs-exploitation-f46af4cf62fe
https://www.digitalocean.com/community/tutorials/how-to-build-atari-bot-with-openai-gym
https://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/
https://medium.com/@ashish_fagna/understanding-openai-gym-25c79c06eccb
• (5 points) Describe the TABU, GENETIC and A* Search algorithm
-
In which category do you classify it. Indicates advantages and disadvantages with the algorithms that have been studied in the classes
-
Which advantages and disadvantages do you discover in this algorithm to solve the traveling salesman problem.
• (1 point) what is overfitting training problem and how to solve it in neural networks and specially in Keras.
• (2 points ) Give an original example of reasoning based on backward chaining.
• (2 points) We want to solve the problem of travelling Sales problem (https://en.wikipedia.org/wiki/Travelling_salesman_problem) , how would you solve it? What algorithm would you use and why? How should the problem be coded to solve it with the "tabu search" algorithm?