安利姐妹篇 对 prefill only models 推理性能调优
- 首字延迟 & 生成延迟
- Decoding (chat) models 推理过程可以分成,预填充 (Prefill) 和解码 (Decoding) 两个阶段
- 预填充 (Prefill) 阶段对应于输出第一个词的的,需要将提示词每个词的中间结果都写入 kv cache 里,才能推理得到第一个词。 这个阶段是对 kv cache 进行预填充。
- 首字延迟(First Token Latency、Time To First Token (TTFT))也就是系统生成第一个字符所需的响应时间
- 解码 (Decoding) 阶段对应于输出之后的 token 的输出。 kv cache 已经填入之前 token。 推理过程就是从下往上过一遍模型,最后从 lm_head 输出 logits 采样。
- 生成延迟(Decoding Latency、Time Per Output Token (TPOT))之后的字符响应时间。
- 推理速度极限
- 现代 CPU/GPU 的 ALU 操作(乘法、加法)内存 IO 速度要快得多,transformer 这种只需要对每个元素执行两次操作的场景,必定受到访存带宽的限制。
- 以 NVIDIA GeForce RTX 4090 为例,1008 GB/s 显存带宽和 83 TFLOPS,Flop:byte = 82:1,算力非常充足。
- 对于解码 (Decoding) 阶段,每输出一个词需要读一遍模型,读取模型的极限就是速度的极限
- 对于预填充 (Prefill) 阶段,读一遍模型计算提示词中的多个词,无论从 SIMD (Single Instruction Multiple Data) 的角度还是从带宽瓶颈 vs 算力瓶颈的角度都很划算
- 更多推理速度极限细节情参考 LLM inference speed of light
- 显存管理
- LLM 输出总长度事先未知,kv cache 需要按需不断增加,为 llm 推理框架增加了不少麻烦。简单的显存管理会产生显存碎片(fragmentation)
- 受到操作系统的虚拟内存分页启发,vLLM 引入了 PagedAttention 减轻 kv cache 的显存碎片。
- 更多显存管理细节情参考
- 大语言模型多用户场景下性能优化技术
- Continuous batching
- LLM 输出总长度不统一,输出短的请求会提前退出,资源空闲,影响整体吞吐率。连续批处理(Continuous batching),当有请求退出,资源空闲时,不等所有请求都完成,中途及时将等待队列中的请求加入到批次中,减少流水线气泡,提高资源利用率,提高整体吞吐率。
- 连续批处理(Continuous batching)的关键是一次模型推理,同时进行解码 (Decoding) 阶段和预填充 (Prefill) 阶段。
- 下图来自 continuous-batching-llm-inference
-
- 可以看到使用连续批处理(Continuous batching) 技术,流水线被填充的满满当当,非常好。
- 更多细节请参考 Orca: A Distributed Serving System for Transformer-Based Generative Models
- Dynamic SplitFuse / Chunked Fill
- 如果一个请求的预填充 (Prefill) 阶段在一次模型中完成,超大的请求会导致解码阶段的用户也要跟着等非常长时间,显然很不合理
- 下图来自 DeepSpeed-FastGen
-

- 更多Dynamic SplitFuse / Chunked Fill 细节请参考:
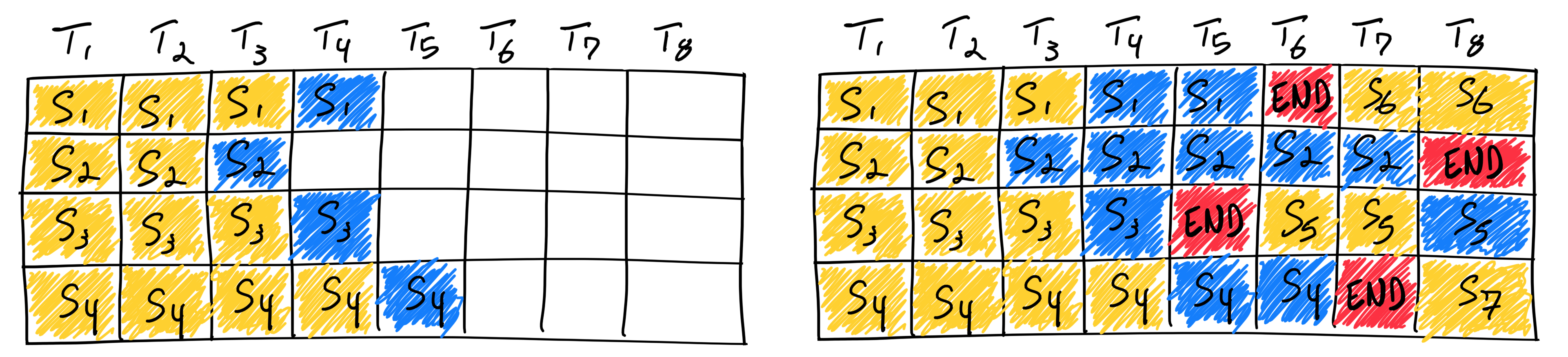
wde 使用 Chunked Fill,所以不区分预填充 (Prefill) 和解码 (Decoding)阶段,也就是一个step既有Prefill阶段的任务,也有Decoding阶段的任务。
一个step的执行时间,基本上只与 max_num_batched_tokens 或者叫 chunked_prefill_size 有关, 具体细节参考 DeepSpeed-FastGen
我一般会通过依次采样多个不同的 max_num_batched_tokens,得到相应的吞吐和响应,绘制吞吐延迟曲线评估推理性能
横坐标为单位qps,纵坐标为延迟单位毫秒。延迟低吞吐高表明模型推理性能好,所以吞吐延迟曲线评估右下更好
吞吐量(Throughput)定义和计算比较明确,单位时间里完成的请求
延迟 (Latency)计算口径比较多,下面每张图每个表的口径都可能不太一样,要注意区分
本文以 Qwen2.5-7B-Instruct fp8模型在单张 4090 推理性能举例
为了更好的对系统性能观察和调优,记录了以下Metrics。一个请求会输出多个token,也就是一个请求会解码多次,请求的一次解码生命周期如下:
时间戳
- arrival_ts:进入系统时间戳
- scheduled_ts:调度器调度时间戳
- first_scheduled_ts:请求第一次被调度的时间戳
- inference_begin_ts:执行器执行开始的时间戳
- inference_end_ts:执行器执行完成的时间戳
- finish_ts:完成的时间戳
通过时间戳可以计算以下时间
- waiting_time = arrival_ts - first_scheduled_ts: 请求在调度前队列里等待的时间
- scheduling2inference = inference_begin_ts - scheduled_ts:从调度到执行的时间
- inference_time = inference_end_ts - inference_begin_ts:执行器推理的时间
- latency = finish_ts - scheduled_ts:从调度到完成的时间
离线批量推理情景下 waiting_time 跟总请求量有关,一般不关注,所以有两个延迟口径需要关注:
- inference_time = inference_end_ts - inference_begin_ts:执行器推理的时间
- latency = finish_ts - scheduled_ts:从调度到完成的时间
python -m benchmarks.chat.profiler.profiling_decoding
使用 chrome://tracing/ 查看 sync-1-1.json ~ sync-1-64.json

图1 对于轻负载,两个线程 cuda kernels launch 肯定比一个效率高,应该能有不错的加速效果
图2 对于重负载,不是每次都会添加新request,而两次解码需要的CPU处理时间非常短,异步调度估计提高有限

图3 放大对于7B-fp8的模型,一个step时间大概14ms,其中cpu部分比如调度预处理后处理才0.3ms

图4 1.5B的模型,一个step时间大概6ms,0.3ms也是不值一提
所以简单的实现异步调度几乎不会提高吞吐, 尤其是考虑到GIL的影响,甚至会导致性能下降
异步调度优化QPS的原理请移步 对 prefill only models 推理性能调优
直接对着图说吧

图5 延迟口径是inference_time

图6 延迟口径是latency

图7 与其他系统 QPS对比
- max_num_batched_tokens = 32 时,async-2 对比 sync QPS 高 8%
- max_num_batched_tokens = 768 时 对比 sync QPS 低 2%
- max_num_batched_tokens = 1024 时出现抢占
- max_num_batched_tokens = 1536 时 oom
- 7B-bf16 压力测试对于 24G 的 4090 来说还是太大了

图8 延迟口径是inference_time
- simple_async 和 async-1,几乎没有性能提升,甚至有性能下降
- max_num_batched_tokens = 32 时,async-2 对比 sync QPS高22%
- max_num_batched_tokens = 1536 时, async-2 对比 sync QPS几乎相同,这时GPU饱和
- 所以提高GPU利用率最好的办法是加大 batchsize

图9 延迟口径是latency
- async-2 延迟是 sync 的两倍
- async-3 对比 async-2 几乎没有QPS提升,但延迟是sync的两倍

图10 与其他系统 QPS对比
7B-fp8 QPS 几乎是 bf16 的两倍,所有测评显示fp8推理对性能没有损失,fp8是最佳的推理选择

图11 延迟口径是inference_time

图12 延迟口径是latency

图13 与其他系统 QPS对比
- max_num_batched_tokens = 32 时,async-2 对比 sync QPS 高 23%
- max_num_batched_tokens = 768 时,async-2 对比 sync QPS 高 5%
- max_num_batched_tokens = 1024 时,async-2 与 sync 相同
- max_num_batched_tokens = 1536 时,async-2 对比 sync QPS 低 2%
异步调度对小模型低负载效果比较好,大模型高负载几乎没有效果