删除单链表元素 #4
Description
链表节点定义如下:
typedef struct node {
int val;
struct node* next;
} Node;一般而言,删除链表中指定元素的算法是这样的:
void remove_list_entry_2(Node* entry) {
Node *prev, *cur = head;
while (cur != entry) {
prev = cur;
cur = cur->next;
}
if (prev) {
prev->next = entry->next;
} else {
head = entry->next;
}
}下面的代码可以避免if-else逻辑:
void remove_list_entry_1(Node* entry) {
Node** indirect = &head;
while ((*indirect) != entry) {
indirect = &(*indirect)->next;
}
*indirect = entry->next;
}下面的代码,虽然思路和上一个差不多,却不能实现同样的效果,原因是最后修改的值,并不是在链表中元素真正存储的地址,只是它的一个副本,所以修改没有体现到原链表上。
void remove_list_entry_3(Node* entry) {
Node* p = head;
while (p != entry) {
p = p->next;
}
// printf("equal: %d %d %d\n", (p == head), (entry == head), (p == entry));
// printf("equal: %d %d %d\n", (&p == &head), (&entry == &head), (&p == &entry));
Node** pptt = &p;
*pptt = entry->next;
}这里的错误地方在于,虽然p的值和entry是相等的,但是我们修改的*pptt只是这个p的地址,修改了这个地址不会导致原有的在链表上的地址发生变化,所以无法打成我们想要的效果;
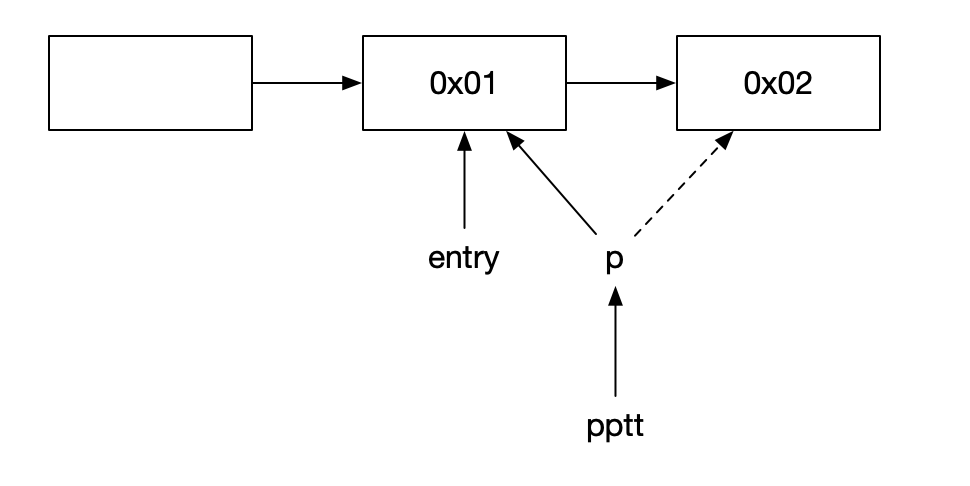
如上图所示,当我们找到了待删除的元素后,p的指向是正确的,但是我们通过获取p的地址pptt,然后再来*pptt修改p的值,对原始链表是没有任何影响的。比较上述两种做法,就会对这一方法理解的更为深刻。
这是Linus在一次演讲中举的一个例子,为的是说明代码的品味(taste)以及好的设计的重要性,这种比较新奇的写法,可以避免if-else判断,也就是将特殊情况融合到了一般情况中,是一个比较优雅的设计。他也说了,这个小小的例子不足以设计好的设计的重要性,在更实际的项目中,好的设计和品味带来的效果是更加无穷的。同时,对于同一种问题,要think differently,从不同的角度来看待问题。