SELECT *
FROM table_name;SELECT column1, column2, ...
FROM table_name;SELECT DISTINCT column1, column2, ...
FROM table_name;SELECT column1, column2, ...
FROM table_name
WHERE condition;Check Operators in The WHERE Clause

SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND condition3 ...;
-----------------------------------------------------
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR condition3 ...;
-----------------------------------------------------
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;SELECT
column_list
FROM
table1
ORDER BY column_list
LIMIT row_count OFFSET limit;For example:
SELECT
employee_id, first_name, last_name
FROM
employees
ORDER BY first_name
LIMIT 5 OFFSET 3;
SELECT column_names
FROM table_name
WHERE column_name IS NULL;SELECT column_names
FROM table_name
WHERE column_name IS NOT NULL;UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;For example:
UPDATE Customers
SET ContactName = 'Alfred Schmidt', City= 'Frankfurt'
WHERE CustomerID = 1;Note that it start with delete from:
DELETE FROM table_name
WHERE condition;SELECT MIN(column_name)
FROM table_name
WHERE condition;
-----------------------------------------------------
SELECT MAX(column_name)
FROM table_name
WHERE condition;
-----------------------------------------------------
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
-----------------------------------------------------
SELECT AVG(column_name)
FROM table_name
WHERE condition;
-----------------------------------------------------
SELECT SUM(column_name)
FROM table_name
WHERE condition;SELECT column1, column2, ...
FROM table_name
WHERE columnN LIKE pattern;
SELECT * FROM Customers
WHERE CustomerName LIKE 'a%';SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);or
SELECT column_name(s)
FROM table_name
WHERE column_name IN (SELECT STATEMENT);For example:
SELECT * FROM Customers
WHERE Country IN (SELECT Country FROM Suppliers);SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name
WHERE condition;Self Join
SELECT column_name(s)
FROM table1 T1, table1 T2
WHERE condition;SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;The UNION operator selects only distinct values by default. To allow duplicate values, use UNION ALL
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);For example:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;The HAVING clause was added to SQL because the WHERE keyword cannot be used with aggregate functions.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;TO_NUMBER('1210.73', '9999.99')
Result: 1210.73
TO_NUMBER('546', '999')
Result: 546
TO_NUMBER('23', '99')
Result: 23General formula:
WINDOW_FUNCTION() OVER (
[PARTITION BY <COLUMN>]
[ORDER BY <COLUMN>]
[ ROWS BETWEEN N PRECEDING AND CURRENT ROW] OR [ROWS BETWEEN CURRENT AND N FOLLOWING])
AS
<ALIAS>Short version:
WINDOW_FUNCTION() OVER (PARTITION BY <COLUMN>)
AS
<ALIAS>
-
DENSE_RANK(): Computes the rank of a certain element in a given list of elements or column where this would be consecutive to the previous rank.
-
RANK(): Computes the rank of a certain element in a given list of elements or column where the current rank need not be of a consecutive rank to the previous rank.
-
ROW_NUMBER(): returns the sequential number of a row within a partition of a result set, starting at 1 for the first row in each partition.
For example:

The result is:

Lead and Lag:
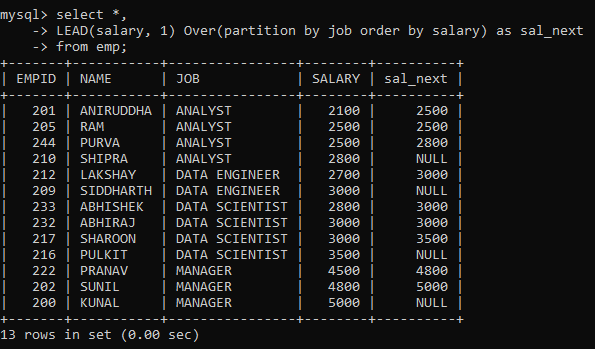
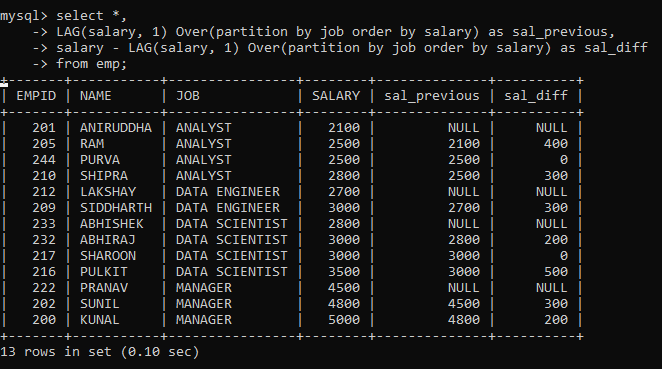
SELECT
(
(SELECT MAX(Score) FROM
(SELECT TOP 50 PERCENT Score FROM Posts ORDER BY Score) AS BottomHalf)
+
(SELECT MIN(Score) FROM
(SELECT TOP 50 PERCENT Score FROM Posts ORDER BY Score DESC) AS TopHalf)
) / 2 AS MedianDECLARE
@start_dt DATETIME2= '2019-12-31 23:59:59.9999999',
@end_dt DATETIME2= '2020-01-01 00:00:00.0000000';
SELECT
DATEDIFF(year, @start_dt, @end_dt) diff_in_year,
DATEDIFF(quarter, @start_dt, @end_dt) diff_in_quarter,
DATEDIFF(month, @start_dt, @end_dt) diff_in_month,
DATEDIFF(dayofyear, @start_dt, @end_dt) diff_in_dayofyear,
DATEDIFF(day, @start_dt, @end_dt) diff_in_day,
DATEDIFF(week, @start_dt, @end_dt) diff_in_week,
DATEDIFF(hour, @start_dt, @end_dt) diff_in_hour,
DATEDIFF(minute, @start_dt, @end_dt) diff_in_minute,
DATEDIFF(second, @start_dt, @end_dt) diff_in_second,
DATEDIFF(millisecond, @start_dt, @end_dt) diff_in_millisecond;https://stackoverflow.com/questions/3491329/group-by-with-maxdate
SELECT train, dest, time FROM (
SELECT train, dest, time,
RANK() OVER (PARTITION BY train ORDER BY time DESC) dest_rank
FROM traintable
) where dest_rank = 1reference (similar as the above one)
WITH Cte AS(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY one_column ORDER BY Time_column DESC) Rn
FROM Table
)
DELETE FROM Cte WHERE Rn = 1;