On the top-level page for a dataset we are proposing a design that aims to give a user (data consumer) an overview of the dataset. This includes what schemas make up the dataset and samples of data for each of the schemas.
As well as attempting to help the user understand the shape of the dataset we also want to generate trust in the data. We want a user to feel confident our data is reliable, they can trust it and that they can use it easily.
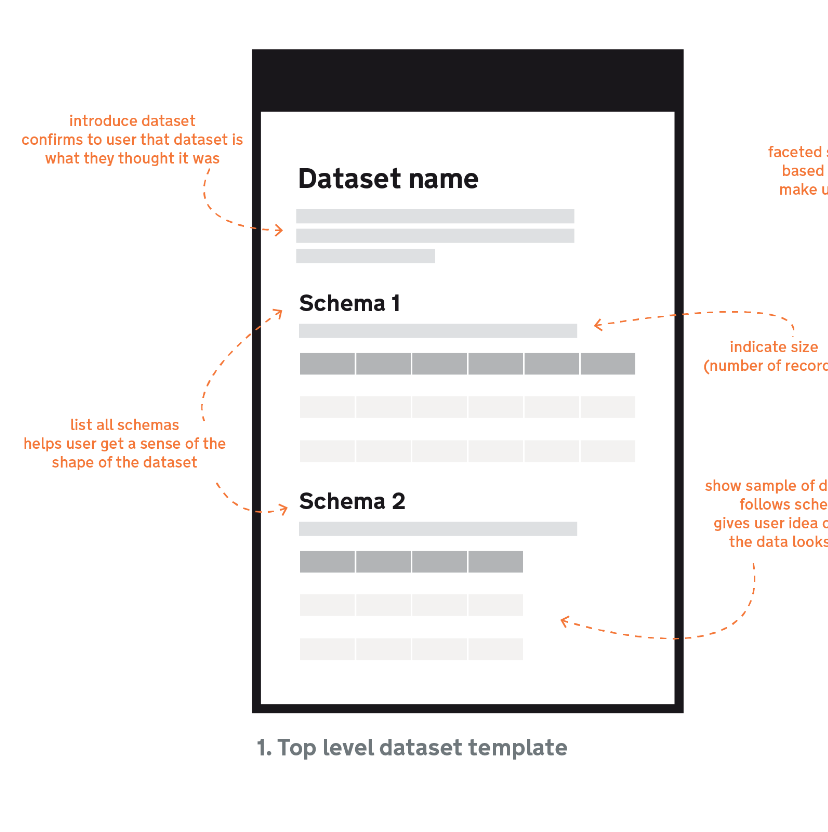
We are trying to work out what data we should use for the “samples.”
The easiest and probably sensible first approach is to take the first X (we still need to decide on the optimum number of rows to show per schema) rows from the file containing the data and display them as the sample.
However, if the rows selected for the sample contain errors or are incomplete then it might lead to a bad outcome. It might lead to the user believing the dataset is of poor quality, and ultimately, dissuade them from using it.
To mitigate the above we could “editorially” choose rows of data to display. But this comes with its
own downsides, in particular, the overhead of maintaining it.
This is a thread for discussing how we will tackle this.
On the top-level page for a dataset we are proposing a design that aims to give a user (data consumer) an overview of the dataset. This includes what schemas make up the dataset and samples of data for each of the schemas.
As well as attempting to help the user understand the shape of the dataset we also want to generate trust in the data. We want a user to feel confident our data is reliable, they can trust it and that they can use it easily.
We are trying to work out what data we should use for the “samples.”
The easiest and probably sensible first approach is to take the first X (we still need to decide on the optimum number of rows to show per schema) rows from the file containing the data and display them as the sample.
However, if the rows selected for the sample contain errors or are incomplete then it might lead to a bad outcome. It might lead to the user believing the dataset is of poor quality, and ultimately, dissuade them from using it.
To mitigate the above we could “editorially” choose rows of data to display. But this comes with its
own downsides, in particular, the overhead of maintaining it.
This is a thread for discussing how we will tackle this.