Very cool idea!!! How can one contribute? #1
Description
I saw your post on twitter about your new method for attention approximation and I think this is a cool idea! But can you clarify a few things?
Approximation Method: Is your method genuinely approximating attention, or is it fundamentally different? From what I gather, if one intends to use the Random Maclaurin (RM) method while retaining the query (q), key (k), and value (v) components, it would seem similar to approaches like the Performer or the RANDOM FEATURE ATTENTION. These methods approximate the RBF kernel as:
If I understand correctly, methods like these work because they reorganize matrix multiplications, thereby removing the
Query, Key, Value Components: It appears you're not maintaining the traditional query, key, and value framework. How does this approach approximate attention without these components? I initially thought 'h' in your diagram played the role of the queries, but after examining the diagram (linked below), it doesn't seem to be the case. It is more like context. Also why average over the token lengths? Is this how tokens are mixed and communicate with each other?
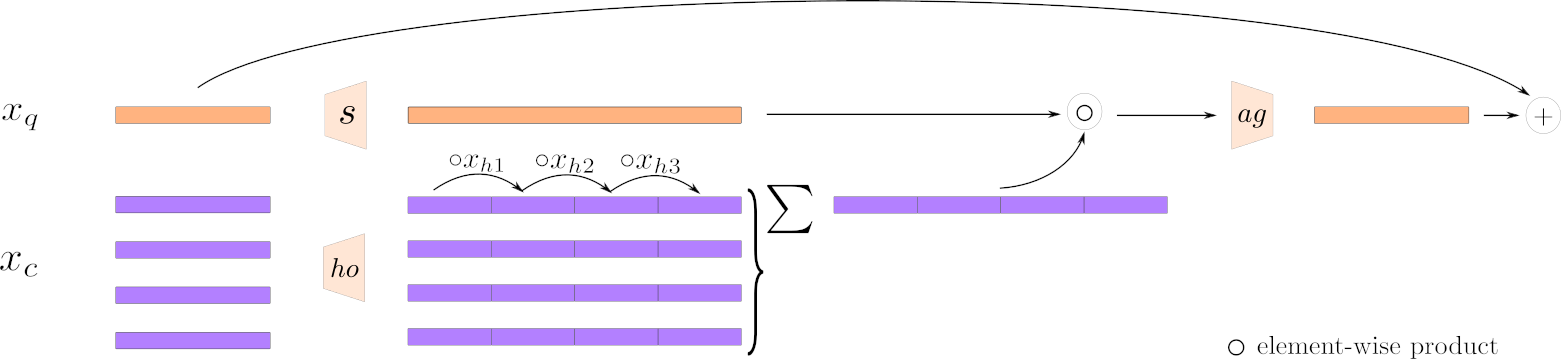
Can you explain more what your algorithm is trying to accomplish? It looks like it's replacing the self-attention mechanism, but does it require additional heads or capacity to become akin to MHA?