Pull schema from Hasura. #2
Description
The Hasura API
has a method for querying the public schema,
which is used by Hasura's web console to display the tables and data inside postgres.
This API is the first thing that is called when the web console loads, as you can see here.
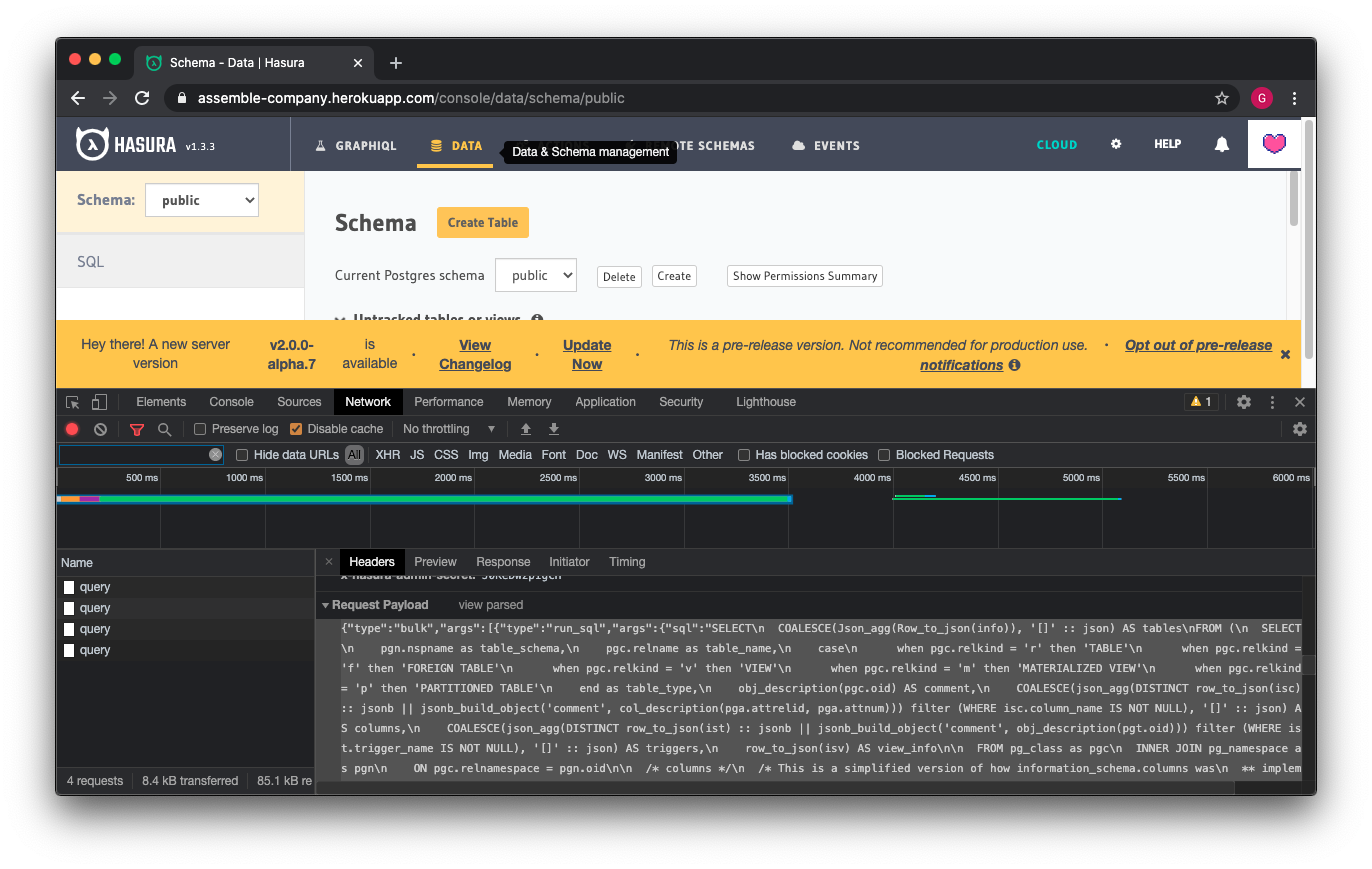
The request hits the following address:
https://assemble-public.herokuapp.com/v1/query
and has the payload:
{
"type": "bulk",
"args": [
{
"type": "run_sql",
"args": {
"sql": "SELECT\n COALESCE(Json_agg(Row_to_json(info)), '[]' :: json) AS tables\nFROM (\n SELECT\n pgn.nspname as table_schema,\n pgc.relname as table_name,\n case\n when pgc.relkind = 'r' then 'TABLE'\n when pgc.relkind = 'f' then 'FOREIGN TABLE'\n when pgc.relkind = 'v' then 'VIEW'\n when pgc.relkind = 'm' then 'MATERIALIZED VIEW'\n when pgc.relkind = 'p' then 'PARTITIONED TABLE'\n end as table_type,\n obj_description(pgc.oid) AS comment,\n COALESCE(json_agg(DISTINCT row_to_json(isc) :: jsonb || jsonb_build_object('comment', col_description(pga.attrelid, pga.attnum))) filter (WHERE isc.column_name IS NOT NULL), '[]' :: json) AS columns,\n COALESCE(json_agg(DISTINCT row_to_json(ist) :: jsonb || jsonb_build_object('comment', obj_description(pgt.oid))) filter (WHERE ist.trigger_name IS NOT NULL), '[]' :: json) AS triggers,\n row_to_json(isv) AS view_info\n\n FROM pg_class as pgc\n INNER JOIN pg_namespace as pgn\n ON pgc.relnamespace = pgn.oid\n\n /* columns */\n /* This is a simplified version of how information_schema.columns was\n ** implemented in postgres 9.5, but modified to support materialized\n ** views.\n */\n LEFT OUTER JOIN pg_attribute AS pga\n ON pga.attrelid = pgc.oid\n LEFT OUTER JOIN (\n SELECT\n current_database() AS table_catalog,\n nc.nspname AS table_schema,\n c.relname AS table_name,\n a.attname AS column_name,\n a.attnum AS ordinal_position,\n pg_get_expr(ad.adbin, ad.adrelid) AS column_default,\n CASE WHEN a.attnotnull OR (t.typtype = 'd' AND t.typnotnull) THEN 'NO' ELSE 'YES' END AS is_nullable,\n CASE WHEN t.typtype = 'd' THEN\n CASE WHEN bt.typelem <> 0 AND bt.typlen = -1 THEN 'ARRAY'\n WHEN nbt.nspname = 'pg_catalog' THEN format_type(t.typbasetype, null)\n ELSE 'USER-DEFINED' END\n ELSE\n CASE WHEN t.typelem <> 0 AND t.typlen = -1 THEN 'ARRAY'\n WHEN nt.nspname = 'pg_catalog' THEN format_type(a.atttypid, null)\n ELSE 'USER-DEFINED' END\n END AS data_type,\n CASE WHEN nco.nspname IS NOT NULL THEN current_database() END AS collation_catalog,\n nco.nspname AS collation_schema,\n co.collname AS collation_name,\n CASE WHEN t.typtype = 'd' THEN current_database() ELSE null END AS domain_catalog,\n CASE WHEN t.typtype = 'd' THEN nt.nspname ELSE null END AS domain_schema,\n CASE WHEN t.typtype = 'd' THEN t.typname ELSE null END AS domain_name,\n current_database() AS udt_catalog,\n coalesce(nbt.nspname, nt.nspname) AS udt_schema,\n coalesce(bt.typname, t.typname) AS udt_name,\n a.attnum AS dtd_identifier,\n CASE WHEN c.relkind = 'r' OR\n (c.relkind IN ('v', 'f', 'p') AND\n pg_column_is_updatable(c.oid, a.attnum, false))\n THEN 'YES' ELSE 'NO' END AS is_updatable\n FROM (pg_attribute a LEFT JOIN pg_attrdef ad ON attrelid = adrelid AND attnum = adnum)\n JOIN (pg_class c JOIN pg_namespace nc ON (c.relnamespace = nc.oid)) ON a.attrelid = c.oid\n JOIN (pg_type t JOIN pg_namespace nt ON (t.typnamespace = nt.oid)) ON a.atttypid = t.oid\n LEFT JOIN (pg_type bt JOIN pg_namespace nbt ON (bt.typnamespace = nbt.oid))\n ON (t.typtype = 'd' AND t.typbasetype = bt.oid)\n LEFT JOIN (pg_collation co JOIN pg_namespace nco ON (co.collnamespace = nco.oid))\n ON a.attcollation = co.oid AND (nco.nspname, co.collname) <> ('pg_catalog', 'default')\n WHERE (NOT pg_is_other_temp_schema(nc.oid))\n AND a.attnum > 0 AND NOT a.attisdropped AND c.relkind in ('r', 'v', 'm', 'f', 'p')\n AND (pg_has_role(c.relowner, 'USAGE')\n OR has_column_privilege(c.oid, a.attnum,\n 'SELECT, INSERT, UPDATE, REFERENCES'))\n ) AS isc\n ON isc.table_schema = pgn.nspname\n AND isc.table_name = pgc.relname\n AND isc.column_name = pga.attname\n\n /* triggers */\n LEFT OUTER JOIN pg_trigger AS pgt\n ON pgt.tgrelid = pgc.oid\n LEFT OUTER JOIN information_schema.triggers AS ist\n ON ist.event_object_schema = pgn.nspname\n AND ist.event_object_table = pgc.relname\n AND ist.trigger_name = pgt.tgname\n\n /* This is a simplified version of how information_schema.views was\n ** implemented in postgres 9.5, but modified to support materialized\n ** views.\n */\n LEFT OUTER JOIN (\n SELECT\n current_database() AS table_catalog,\n nc.nspname AS table_schema,\n c.relname AS table_name,\n CASE WHEN pg_has_role(c.relowner, 'USAGE') THEN pg_get_viewdef(c.oid) ELSE null END AS view_definition,\n CASE WHEN 'check_option=cascaded' = ANY (c.reloptions) THEN 'CASCADED'\n WHEN 'check_option=local' = ANY (c.reloptions) THEN 'LOCAL'\n ELSE 'NONE'\n END AS check_option,\n CASE WHEN pg_relation_is_updatable(c.oid, false) & 20 = 20 THEN 'YES' ELSE 'NO' END AS is_updatable,\n CASE WHEN pg_relation_is_updatable(c.oid, false) & 8 = 8 THEN 'YES' ELSE 'NO' END AS is_insertable_into,\n CASE WHEN EXISTS (SELECT 1 FROM pg_trigger WHERE tgrelid = c.oid AND tgtype & 81 = 81) THEN 'YES' ELSE 'NO' END AS is_trigger_updatable,\n CASE WHEN EXISTS (SELECT 1 FROM pg_trigger WHERE tgrelid = c.oid AND tgtype & 73 = 73) THEN 'YES' ELSE 'NO' END AS is_trigger_deletable,\n CASE WHEN EXISTS (SELECT 1 FROM pg_trigger WHERE tgrelid = c.oid AND tgtype & 69 = 69) THEN 'YES' ELSE 'NO' END AS is_trigger_insertable_into\n FROM pg_namespace nc, pg_class c\n\n WHERE c.relnamespace = nc.oid\n AND c.relkind in ('v', 'm')\n AND (NOT pg_is_other_temp_schema(nc.oid))\n AND (pg_has_role(c.relowner, 'USAGE')\n OR has_table_privilege(c.oid, 'SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES, TRIGGER')\n OR has_any_column_privilege(c.oid, 'SELECT, INSERT, UPDATE, REFERENCES'))\n ) AS isv\n ON isv.table_schema = pgn.nspname\n AND isv.table_name = pgc.relname\n\n WHERE\n pgc.relkind IN ('r', 'v', 'f', 'm', 'p')\n and (pgn.nspname='public')\n GROUP BY pgc.oid, pgn.nspname, pgc.relname, table_type, isv.*\n) AS info;",
"cascade": false,
"read_only": true
}
},
{
"type": "select",
"args": {
"table": {
"name": "hdb_table",
"schema": "hdb_catalog"
},
"columns": [
"table_schema",
"table_name",
"is_enum",
"configuration",
{
"name": "primary_key",
"columns": [
"*"
]
},
{
"name": "relationships",
"columns": [
"*"
]
},
{
"name": "permissions",
"columns": [
"*"
]
},
{
"name": "unique_constraints",
"columns": [
"*"
]
},
{
"name": "check_constraints",
"columns": [
"*"
],
"order_by": {
"column": "constraint_name",
"type": "asc"
}
},
{
"name": "computed_fields",
"columns": [
"*"
],
"order_by": {
"column": "computed_field_name",
"type": "asc"
}
}
],
"order_by": [
{
"column": "table_name",
"type": "asc"
}
]
},
"where": {
"$or": [
{
"table_schema": "public"
}
]
}
},
{
"type": "run_sql",
"args": {
"sql": "select\n COALESCE(\n json_agg(\n row_to_json(info)\n ),\n '[]' :: JSON\n ) AS tables\nFROM\n (\n select\n hdb_fkc.*,\n fk_ref_table.table_name IS NOT NULL AS is_ref_table_tracked\n from\n hdb_catalog.hdb_table AS ist\n JOIN hdb_catalog.hdb_foreign_key_constraint AS hdb_fkc ON hdb_fkc.table_schema = ist.table_schema\n and hdb_fkc.table_name = ist.table_name\n LEFT OUTER JOIN hdb_catalog.hdb_table AS fk_ref_table ON fk_ref_table.table_schema = hdb_fkc.ref_table_table_schema\n and fk_ref_table.table_name = hdb_fkc.ref_table\n where (ist.table_schema='public')\n ) as info;",
"cascade": false,
"read_only": true
}
},
{
"type": "run_sql",
"args": {
"sql": "select\n COALESCE(\n json_agg(\n row_to_json(info)\n ),\n '[]' :: JSON\n ) AS tables\nFROM\n (\n select DISTINCT ON (hdb_fkc.constraint_oid)\n hdb_fkc.*,\n fk_ref_table.table_name IS NOT NULL AS is_table_tracked,\n hdb_uc.constraint_name IS NOT NULL AS is_unique\n from\n hdb_catalog.hdb_table AS ist\n JOIN hdb_catalog.hdb_foreign_key_constraint AS hdb_fkc ON hdb_fkc.ref_table_table_schema = ist.table_schema\n and hdb_fkc.ref_table = ist.table_name\n LEFT OUTER JOIN hdb_catalog.hdb_table AS fk_ref_table ON fk_ref_table.table_schema = hdb_fkc.table_schema\n and fk_ref_table.table_name = hdb_fkc.table_name\n LEFT OUTER JOIN hdb_catalog.hdb_unique_constraint AS hdb_uc ON hdb_uc.table_schema = hdb_fkc.table_schema\n and hdb_uc.table_name = hdb_fkc.table_name and ARRAY(select json_array_elements_text(hdb_uc.columns) ORDER BY json_array_elements_text) = ARRAY(select json_object_keys(hdb_fkc.column_mapping) ORDER BY json_object_keys)\n where (ist.table_schema='public')\n ) as info;",
"cascade": false,
"read_only": true
}
},
{
"type": "select",
"args": {
"table": {
"schema": "hdb_catalog",
"name": "hdb_remote_relationship"
},
"columns": [
"*.*",
"remote_relationship_name"
],
"where": {
"$and": [
{
"table_schema": "public"
}
]
},
"order_by": [
{
"column": "remote_relationship_name",
"type": "asc"
}
]
}
}
]
}We need to pare this query down, so our Grid view can display only the necessary rows and columns for each table.
This makes sense; in essence we are copying the features of Hasura's web console,
only with more of a focus on making a nice, AirTable-like experience.
Finding the data schema is only a beginning place.