This paradigm typically involves two key components: generating actions from the current state, and transitioning between states by executing those actions.
📄 ViperGPT
- Title: ViperGPT: Visual Inference via Python Execution for Reasoning
- Venue: ICCV 2023
- GitHub: Link

- Title: Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
- Venue: NeurIPS 2023
- GitHub: Link

📄 Visprog
- Title: Visual Programming: Compositional visual reasoning without training
- Venue: CVPR 2023
- GitHub: Link

- Title: Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
- Venue: arXiv 2023
- GitHub: Link

- Title: HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
- Venue: NeurIPS 2023
- GitHub: Link

- Title: GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction
- Venue: NeurIPS 2023
- GitHub: Link

- Title: InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language
- Venue: arXiv 2023
- GitHub: Link

📄 ViotGPT
- Title: VIoTGPT: Learning to Schedule Vision Tools Towards Intelligent Video Internet of Things
- Venue: AAAI 2025
- GitHub: Link
📄 MM-REACT
- Title: MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
- Venue: arXiv 2023
- GitHub: Link
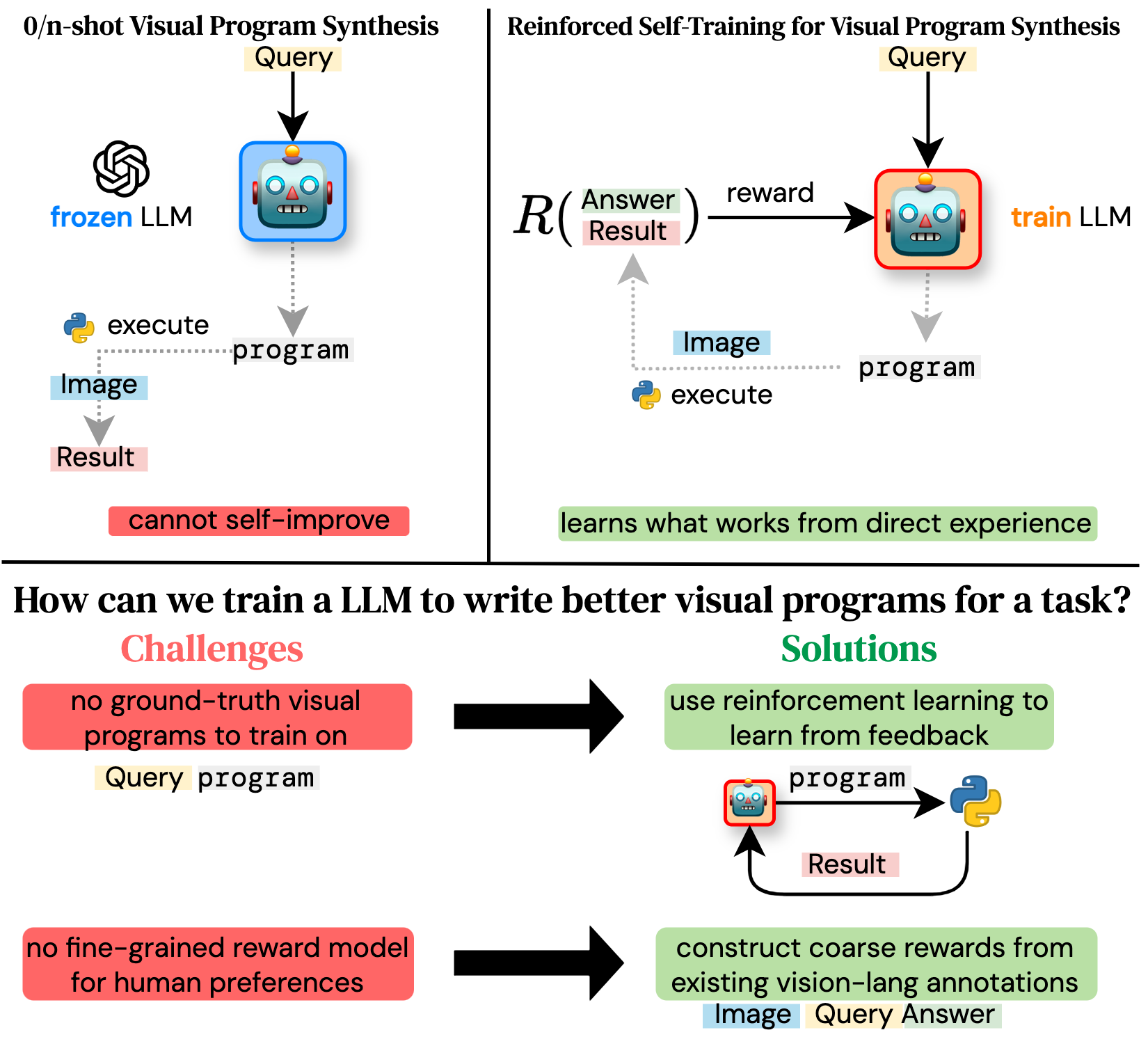
📄 VisRep
- Title: Self-training large language models for improved visual program synthesis with visual reinforcement
- Venue: CVPR 2024
📄 CRAFT
- Title: CRAFT: Customizing LLMs by Creating and Retrieving from Specialized Toolsets
- Venue: ICLR 2024
- GitHub: Link

📄 CLOVA
- Title: CLOVA: A Closed-LOop Visual Assistant with Tool Usage and Update
- Venue: CVPR 2024
- GitHub: Link

📄 HYDRA
- Title: HYDRA
- Venue: ECCV 2024
- GitHub: Link

- Title: ContextualCoder: Adaptive In-context Prompting for Programmatic Visual Question Answering
- Venue: TMM 2025
📄 ViUniT
- Title: Visual Unit Tests for More Robust Visual Programming
- Venue: CVPR 2025
- GitHub: Link

📄 SYNAPSE
- Title: SYNAPSE: SYmbolic Neural-Aided Preference Synthesis Engine
- Venue: AAAI 2025
- GitHub: Link

📄 Naver
- Title: NAVER: A Neuro-Symbolic Compositional Automaton for Visual Grounding with Explicit Logic Reasoning
- Venue: ICCV 2025
- GitHub: Link

- Title: DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
- Venue: ICCV 2025
- GitHub: Link
- Website: Link

📄 LEFT
- Title: What’s Left? Concept Grounding with Logic-Enhanced Foundation Models
- Venue: NeurIPS 2023
- GitHub: Link
