Tweaking pytesseract: OCR confidence threshold and others #3
Description
A key concern for ocirs is how accurate the data returned during table extraction can be. A good chunk of that relies on ocirs' table structure recognition and extraction process. But at an even more basic level, we want to make sure pytesseract, which performs ocr on the form 990 pages, is producing the best possible output for our users purposes.
Take this poor-quality borderless table

And the output that is produced after CascadeTabNet cropping and borderless table extraction.
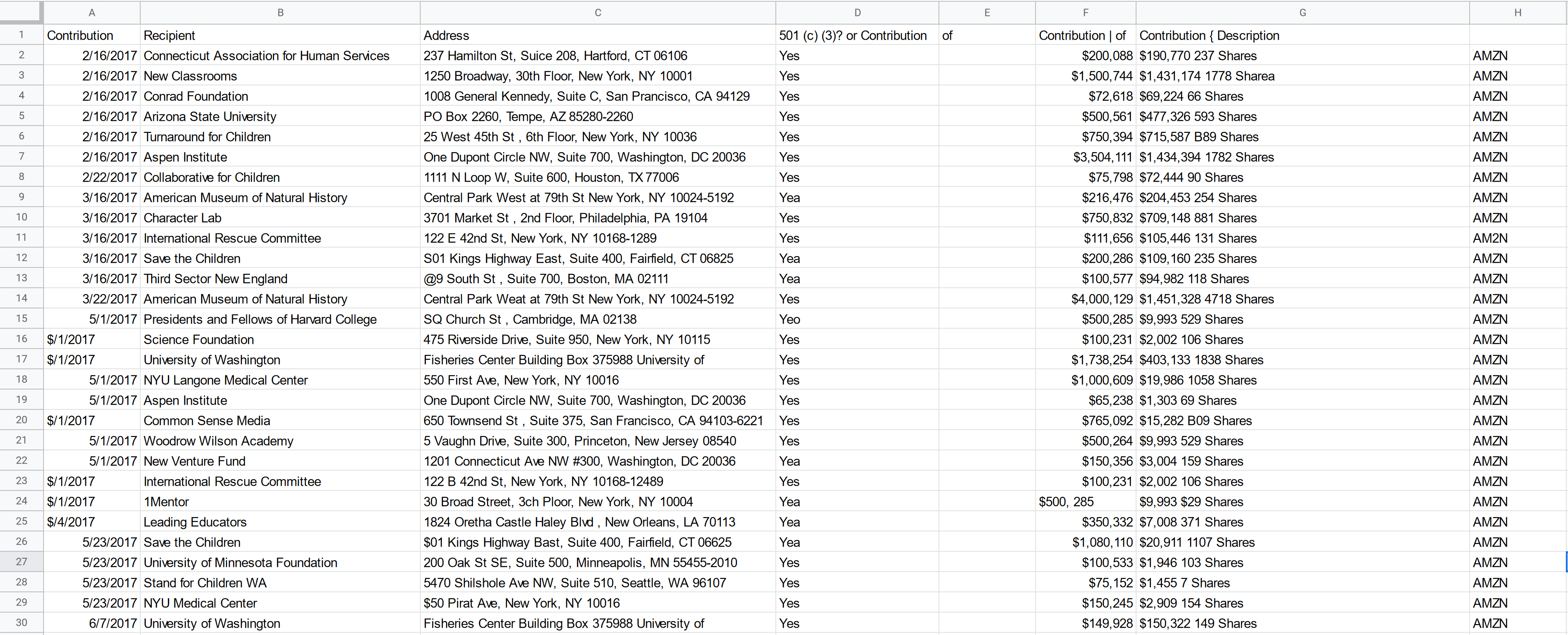
Note the sixth line item listed, the "Aspen Institute." On the original image, we see that the fair market value of the contribution they received is (most likely) $1,504,111. However, when we look at the CSV output we see that pytesseract identified that value to be $3,504,111. It's one wrong character, but a $2 million difference.
As we continue to develop ocirs, we should also identify ways we can improve the accuracy of pytesseract.
For example, we can make the image preprocessing, prior to ocr'ing more robust. Currently, we use the following method from ocirs/image_utils.py.
def ocr_preprocess(image):
'''Preprocessing for an image for pytesseract after it is already loaded through cv2
'''
ret3, thresholded_image = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
ocr_image = cv2.cvtColor(thresholded_image, cv2.COLOR_BGR2RGB)
return ocr_image
This method is called during the instantiation of a NineNinetyPage object (without a data_path) in ocirs/nineninetypage.py.
We can also play around with giving users control over the confidence threshold ocirs uses to filter pytesseract's ocr ouput. When pytesseract produces a dataframe output from an image, it comes with a 'conf' column which indicates how "confident" the program is in a given word it's detected. During our table extraction process, ocirs, filters out all words from the image that are below 0.4 (on a -1 and 0 to 1 scale).
Allowing a path for the user to change that 0.4 value could potentially allow them to tailor ocirs' table extraction output to their person use case. They could set it lower if they'd like to include more data at the risk of seeing more mistakes. They could set it higher if they want to be more confident in the accuracy of the output.
In order to change that value, we can allow users to set the confidence threshold during one of the two main table extraction methods, NineNinetyForm().extract_component_tables() and NineNinetyPage().extract_tables(). Then, we'd need to propagate that variable down to where it is utilized, in get_text_boxes() stored inside ocirs/table_extraction/borderless_table_extraction.py.
All this being said, simply upping the confidence threshold won't automatically make that data extracted by ocirs publishable without careful review.
This is the output from that same 990 form page, this time with the confidence threshold set to 0.95.
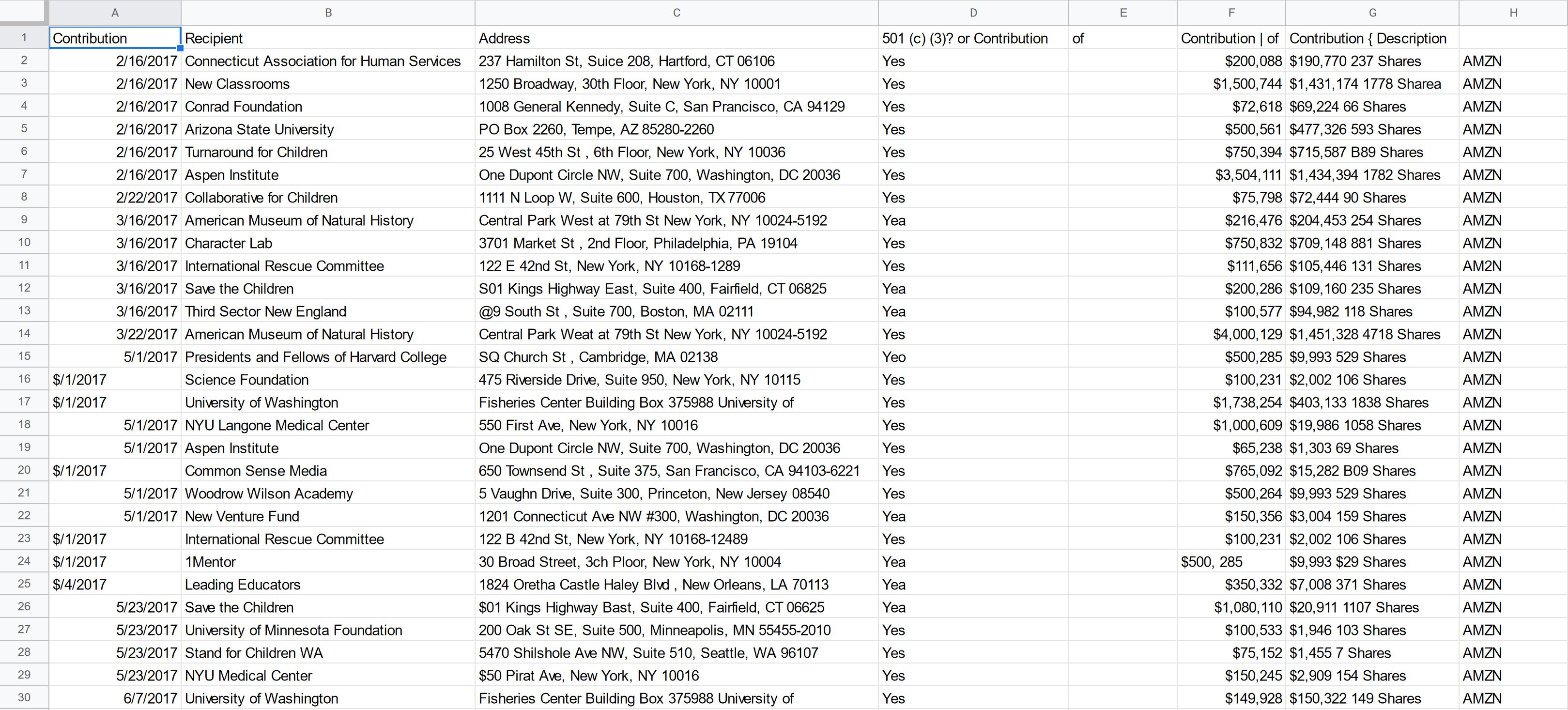
As you can see, the $2 million error is still there.