- Title: A Simple Framework for Contrastive Learning of Visual Representations
- Publication: ICML, 2020
- Link: [paper] [code]
- composition of multiple data augmentations
- learnable nonlinear transformation
- contrastive cross entropy loss
- larger batch sizes and longer training
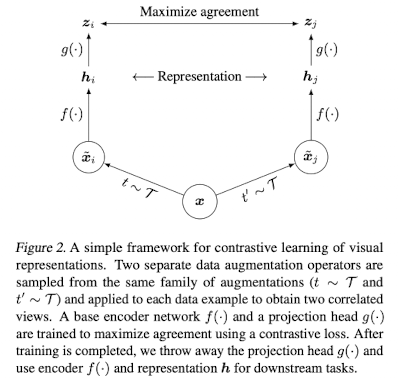
- maximize agreement between differently augmented views of the same data
- Data augmentation : cropping, color distortions, Gaussian blur...
- Neural network base encoder f(·) : extract representation vectors -> adopt ResNet
- Small neural network projection head g(·) : use MLP with 1 hidden layer
- Contrastive Loss function : Maximize agreement
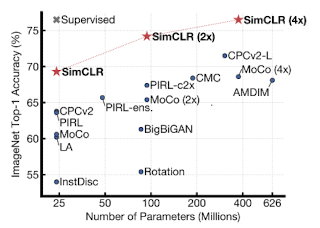
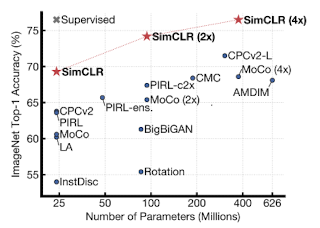
- crucial for learning good representations
- spatial/geometric transformation : cropping, resizing, horizontal flipping, rotation, cutout
- appearance transformation : color distortion, color dropping, brightness, contrast, saturation, hue, Gaussian blur, Sobel filtering

- no single transform suffices to learn good representations
- contrastive prediction task harder, but quality of representation improves dramatically
- stand out : random cropping & color distortion
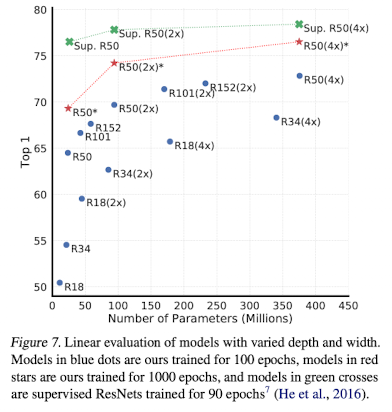
- unsupervised learning benefits more from bigger models than its supervised counterpart
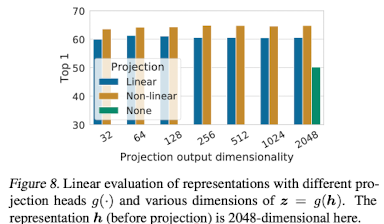
- using non-linear projection : better than linear projection & no projection
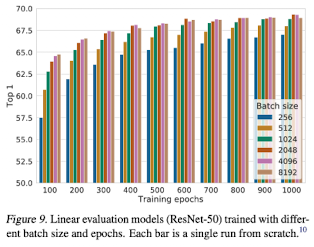
- larger batch sizes & training longer : provide more negative examples -> signifiant advantage
@article{DBLP:journals/corr/abs-2002-05709,
author = {Ting Chen and
Simon Kornblith and
Mohammad Norouzi and
Geoffrey E. Hinton},
title = {A Simple Framework for Contrastive Learning of Visual Representations},
journal = {CoRR},
volume = {abs/2002.05709},
year = {2020},
url = {https://arxiv.org/abs/2002.05709},
eprinttype = {arXiv},
eprint = {2002.05709},
timestamp = {Fri, 14 Feb 2020 12:07:41 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2002-05709.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}