- Title: Momentum Contrast for Unsupervised Visual Representation Learning
- Publication: CVPR, 2020
- Link: [paper] [code]
- keywords
- negative samples are encoded in queue (dynamic dictionary)
- momentum is updated with the query encoder
- methods
- MoCo trains a visual representation encoder by matching an encoded query q to a dictionary of encoded keys using a contrastive loss
- The size of the dictionary is more important than the batch size.
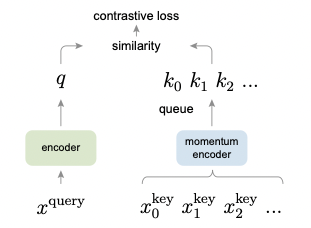
- constrastive loss function (InfoNCE)
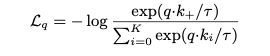
- MoCo is an asymmetric structure, and uses the values stored in the dynamic dictionary as negative samples
- SimCLR, on the other hand, has a symmetrical structure, and uses all images except itself in the batch as negative samples.
- So MoCo doesn't affected by batch size, but SimCLR doesn't.

- end-to-end method calculates the gradient by back-propagation in both directions, and its performance is determined by the batch size.
- memory bank method uses 'memory bank' to store and compare old data using fixed-sized memory.
- MoCo uses momentum to create a dynamic queue and use it to learn the model.

- Initialize parameters from momentum encoder to parameters from encoder
- Augmentation and delivery of images to be placed on both sides
- augmentation: resize&crop, color jittering(lightness, saturation), horizontal flip, grayscale conversion
- Pass the previously augmented data through the encoder and the moment encoder, respectively
- The Momentus Encoder does not calculate gradient
- Calculate logit for positive pair and negative pair (normalization), InfoNCE loss calculation
- Update the encoder by backpropagating, and update the moment encoder by multiplying the weight by the existing moment parameter m.
- Add the key of this mini batch in the queue, and if the dictionary size is overflowing, pop the oldest key to update the memory bank

- The k on the x-axis represents the number of negative samples
- End-to-end needs to increase the batch size to secure the number of negative samples, but due to memory limitations, it is not easy to grow above 1024
- MoCo method shows better accuracy than end-to-end or memory bank
- MoCo method can improve performance by increasing memory bank size

@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Haoqi Fan and
Yuxin Wu and
Saining Xie and
Ross Girshick},
title = {Momentum Contrast for Unsupervised Visual Representation Learning},
journal = {CVPR},
year = {2020},
url = {https://arxiv.org/pdf/1911.05722},
eprinttype = {arXiv},
eprint = {1911.05722},
}