En el presente documento se presentará el trabajo final del curso Complejidad Algorítmica, el cual consiste en el problema del vendedor viajero o problema del agente viajero (TSP por sus siglas en inglés) , este problema responde a una pregunta ya planteada: dada una lista de ciudades y las distancias entre cada par de ellas, ¿cuál es la ruta más corta posible en la cual el vendedor visita cada ciudad exactamente una vez y al finalizar regresa a la ciudad origen?
Uno de los principales problemas presentes es la cantidad de datos que se manejarán, el procesamiento y análisis de los mismos ya de por sí es complicado de realizar. Además de realizar un algoritmo óptimo que nos ayude a resolver el problema en un tiempo prudencial.
La principal motivación para la solución de este problema es que este problema presenta diferentes aplicaciones o representaciones en la vida cotidiana, uno de los principales ejemplos el de llegar de la forma más rápida de tu casa a la universidad, al trabajo, etc.
El presente proyecto tiene los siguientes objetivos:
•Diseñar un algoritmo que nos permita, dados dos datasets, organizarla en un archivo .csv para que de esta manera, el manejo de la información sea más eficiente, rápido y solo utilizar la información que es relevante para el proyecto.
•Diseñar un algoritmo que permita mediante la información en el archivo, generar la distancia entre las ciudades.
•Diseñar un algoritmo que nos permita mediante la distancia entre los puntos, decidir que ruta se debe tomar para lograr el objetivo principal del problema el cual es recorrer todas las ciudades en la distancia mínima.
•Diseñar un algoritmo que nos ayude a visualizar la ruta escogida, además de obtener un tiempo total de ejecución y saber si el algoritmo elegido es eficiente o no, haciendo uso de varios casos de prueba con diferente cantidad de ciudades en cada uno de ellos.
Los archivos CSV (del inglés comma-separated values) son un tipo de documento en formato abierto sencillo para representar datos en forma de tabla, en las que las columnas se separan por comas y las filas por saltos de línea.
El formato CSV es muy sencillo y no indica un juego de caracteres concreto, ni cómo van situados los bytes, ni el formato para el salto de línea. Estos puntos deben indicarse muchas veces al abrir el archivo, por ejemplo, con una hoja de cálculo.
El formato CSV no está estandarizado. La idea básica de separar los campos con una coma es muy clara, pero se vuelve complicada cuando los valores del campo también contienen comillas dobles o saltos de línea. Las implementaciones de CSV pueden no manejar esos datos, o usar comillas de otra clase para envolver el campo. Pero esto no resuelve el problema: algunos campos también necesitan embeber estas comillas, así que las implementaciones de CSV pueden incluir caracteres o secuencias de escape.
Además, el término "CSV" también denota otros formatos de valores separados por delimitadores que usan delimitadores diferentes a la coma (como los valores separados por tabuladores). Un delimitador que no está presente en los valores de los campos (como un tabulador) mantiene el formato simple. Estos archivos separados por delimitadores alternativos reciben en algunas ocasiones la extensión, aunque este uso sea incorrecto. Esto puede causar problemas en el intercambio de datos, por ello muchas aplicaciones que usan archivos CSV tienen opciones para cambiar el carácter delimitador.

En matemáticas, la distancia euclidiana o euclídea es la distancia "ordinaria" (que se mediría con una regla) entre dos puntos de un espacio euclídeo, la cual se deduce a partir del teorema de Pitágoras.
Por ejemplo, en un espacio bidimensional, la distancia euclidiana entre dos puntos P1 y P2, de coordenadas cartesianas (x1, y1) y (x2, y2) respectivamente, es:


En matemáticas y ciencias de la computación, un grafo es un conjunto de objetos llamados vértices o nodos unidos por enlaces llamados aristas o arcos, que permiten representar relaciones binarias entre elementos de un conjunto. Son objeto de estudio de la teoría de grafos.
Típicamente, un grafo se representa gráficamente como un conjunto de puntos (vértices o nodos) unidos por líneas (aristas). Desde un punto de vista práctico, los grafos permiten estudiar las interrelaciones entre unidades que interactúan unas con otras. Por ejemplo, una red de computadoras puede representarse y estudiarse mediante un grafo, en el cual los vértices representan terminales y las aristas representan conexiones (las cuales, a su vez, pueden ser cables o conexiones inalámbricas). Prácticamente cualquier problema puede representarse mediante un grafo, y su estudio trasciende a las diversas áreas de las ciencias exactas y las ciencias sociales.
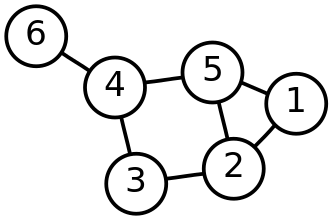
El algoritmo de Kruskal es un algoritmo de la teoría de grafos para encontrar un árbol recubridor mínimo en un grafo conexo y ponderado. Es decir, busca un subconjunto de aristas que, formando un árbol, incluyen todos los vértices y donde el valor de la suma de todas las aristas del árbol es el mínimo. Si el grafo no es conexo, entonces busca un bosque expandido mínimo (un árbol expandido mínimo para cada componente conexa). El algoritmo de Kruskal es un ejemplo de algoritmo voraz que funciona de la siguiente manera: Se crea un bosque B (un conjunto de árboles), donde cada vértice del grafo es un árbol separado Se crea un conjunto C que contenga a todas las aristas del grafo Mientras C es no vacío: Eliminar una arista de peso mínimo de C Si esa arista conecta dos árboles diferentes se añade al bosque, combinando los dos árboles en un solo árbol en caso contrario, se desecha la arista Al acabar el algoritmo, el bosque tiene un solo componente, el cual forma un árbol de expansión mínimo del grafo.
start_time = datetime.now()
n1=25
n2=171
n3=1678
n=3500
#Leyendo el csv
def csvtxtCPR(CPdistsReg):
textl = []
with open('infoCP.csv','r') as ifile:
reader = csv.reader(ifile)
count = 0
for row in reader:
if count != 0:
name = str(count)+","+row[1]+","+row[3]+","+row[15]+","+row[16]+"\n"
textl.append(name)
x = int(float(row[15])*100)
y = int(float(row[16])*100)
CPdistsReg.append((x,y))
if count>n1:
break
count+=1
with open('infoCPRegionales.txt','w') as ofile:
ofile.truncate(0)
for i in textl:
ofile.write(str(i))
file = open('infoCPRegionales.txt', 'r')
print(file.read())
#Calculando las distancias entre los puntos
def euclidean_distance(x1,y1,x2,y2):
return math.sqrt((x1-x2)*(x1-x2)+(y1-y2)*(y1-y2))
#Haciendo las conexiones de cada punto a todos los demás
def connections(vertices):
edges=[[] for _ in range(n1)]
for i in range(n1-1):
for j in range(i+1, n1):
distance=euclidean_distance(vertices[i][0],vertices[i][1],vertices[j][0],vertices[j][1])
edges[i].append((j,distance))
#print(edges)
return edges
w=[]
csvtxtCPR(w)
edges=connections(w)
#Algoritmo de MST
def find(t,a):
if t[a]==a:
return a
else:
grandpa=find(t,t[a])
t[a]=grandpa
return grandpa
def union(t,a,b):
pa=find(t,a)
pb=find(t,b)
t[pb]=pa
def kruskal(G,vertices):
n=len(G)
q=[]
cost=0 #costo total del recorrido
p=[] #para las coordenadas
for u in range(n):
for v,w in G[u]:
hq.heappush(q,(w,u,v))
Gp=[[] for _ in range(n)]
uf=[i for i in range(n)]
while len(q)>0:
w,u,v=hq.heappop(q)
pu=find(uf,u)
pv=find(uf,v)
if pu!=pv:
cost+=w
union(uf,u,v)
p.append((u,v))
Gp[u].append((v,w))
coordinates_path=[]
for i,j in p:
coordinates_path.append((vertices[i][0],vertices[i][1]))
coordinates_path.append((vertices[j][0],vertices[j][1]))
return Gp,cost,coordinates_path
#Agregando las coordenadas del camino obtenido
Gp,cost,coordinates_path=kruskal(edges,w)
x = []
y = []
for i in range(n1):
x.append(coordinates_path[i][0]/100)
y.append(coordinates_path[i][1]/100)
#Cambiar el tamaño del gráfico
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 20
fig_size[1] = 16
#Graficando las coordenadas, el camino y el costo de viaje
plt.plot(x, y, 'b.')
plt.plot(x, y, 'g.--')
plt.show()
print(coordinates_path)
print(cost)
fig = plt.figure(num=None, figsize=(20, 16) )
m = Basemap(width=6000000,height=4500000,resolution='c',projection='aea',lat_1=2.,lat_2=2,lon_0=-75.311132,lat_0=-10.151093)
m.drawcoastlines(linewidth=0.5)
m.fillcontinents(color='tan',lake_color='lightblue')
# draw parallels and meridians.
m.drawparallels(np.arange(-90.,91.,15.),labels=[True,True,False,False],dashes=[2,2])
m.drawmeridians(np.arange(-180.,181.,15.),labels=[False,False,False,True],dashes=[2,2])
m.drawmapboundary(fill_color='lightblue')
m.drawcountries(linewidth=2, linestyle='solid', color='k' )
m.drawstates(linewidth=0.5, linestyle='solid', color='k')
m.drawrivers(linewidth=0.5, linestyle='solid', color='blue')
Gp,cost,coordinates_path=kruskal(edges,w)
xc = []
yc = []
for i in range(n1):
xc.append(coordinates_path[i][0]/100)
yc.append(coordinates_path[i][1]/100)
x,y=m(xc,yc)
m.plot(x,y,'b.', markersize=15)
m.plot(x,y, 'r--', linewidth=3)
plt.title("Perú")
plt.show()
end_time = datetime.now()
print('Duration: {}'.format(end_time - start_time))E:Edge-Arista V:Vertex-Vertice La clasificación de las aristas lleva tiempo O(ELogE). Después de la clasificación, iteramos a través de todos los bordes y aplicamos el algoritmo de union-find. Las operaciones de búsqueda y unión pueden tomar el tiempo O(LogV). Entonces, la complejidad general es el tiempo O(ELogE + ELogV). El valor de E puede ser O(V^2), por lo que O(LogV) y O(LogE) son casi iguales. Por lo tanto, la complejidad global del tiempo es O(ElogE) o O(ElogV).
Las conclusiones del proyecto son las siguientes:
•La generación y uso de los archivos .csv nos permiten y facilitan la gestión y almacenamiento de datos, además de tenerla de forma más ordenada y con fácil acceso a través del Python.
•El problema del TSP, el cual nos indica que debemos recorrer toda una trama de puntos en la distancia más corta, nos ayuda a entender mejor y comprender problemas cotidianos, en los cuales debemos tener en cuenta los recursos, distancia, tiempo y dinero que se invertirán para llegar de un lugar a otro.
•El algoritmo Kruskal es un ejemplo de algoritmo Greedy, por lo que no siempre se encontrará la mejor solución, si no que nos ayudará a encontrar una solución en un tiempo rasonable. Teniendo como complejidad O(ElogE) o O(ElogV).