각각이 언제 쓰이고 무슨 특징과 차이점을 가질까?
보통 Spring에서 개발할 때는 MySQL, Node.js에서는 MongoDB를 주로 사용했을 것이다. 하지만 단순히 프레임워크에 따라 결정하는 것은 아니다. 프로젝트를 진행하기 앞서 적합한 데이터베이스를 택해야 한다
- SQL을 사용하면 RDBMS에서 데이터를 저장, 수정, 삭제 및 검색할 수 있다
- 관계형 데이터베이스에는 핵심적인 두 가지 특징이 있다
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다
- 데이터는 관계를 통해 여러 테이블에 분산된다
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다. 해당 구조는 필드의 이름과 데이터 유형으로 정의된다
따라서 스키마를 준수하지 않는 레코드는 테이블에 추가할 수 없다. 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나이다
또한, 데이터의 중복을 피하기 위해 관계를 이용한다
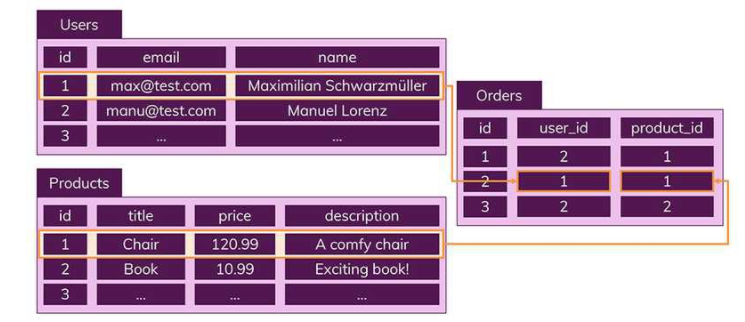
하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 줄어드는 장점이 있다
- 우리가 지금까지 배운 데이터베이스는 RDBMS이다. RDBMS는 데이터의 ACID 속성을 가장 중요시하고 Entity(table)간의 referential constraint 등 테이블의 schema가 미리 정의되어 있다. Big data등 data set이 클 때 distributed database가 제안되긴 했지만 scalability에 이슈가 있다
- DBMS가 제공하는 일부 기능(Consistency)을 포기하고 대신 단순한 그러나 확장성이 좋은 구조를 제공 - Distributed
- 데이터에 대한 Schema를 지정하지 않기 때문에 쉬운 확장성 제공
- SQL에 유사한 query language 제공
- CAP theorem을 사용하여 ACID 속성 중의 일부를 완화
- 말그대로 관계형 DB의 반대이다
- 스키마도 없고 관계도 없다
- NoSQL에서는 레코드를 문서(documents)라고 부른다
여기서 SQL과 핵심적인 차이가 있다. SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능했다
하지만 NoSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다
문서(documents)는 Json과 비슷한 형태로 가지고 있다. 관계형 데이터베이스처럼 여러 테이블에 나누어 담지 않고, 관련 데이터를 동일한 '컬렉션'에 넣는다
따라서 위의 사진의 SQL에서 진행한 Orders, Users, Products 테이블로 나눈 것을 NoSQL에서는 Orders에 한꺼번에 포함해서 저장하게 된다
따라서 여러 테이블에 조인할 필요 없이 이미 필요한 모든 것을 갖춘 문서를 작성하는 것이 NoSQL이다
(NoSQL에는 조인이라는 개념이 존재하지 않는다)
그러면 조인하고 싶을 때 NoSQL은 어떻게 할까?
컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 한다
하지만, 이러면 데이터가 중복되어 서로 영향을 줄 위험이 있다. 따라서 조인을 잘 사용하지 않고 자주 변경되지 않는 데이터일 때, NoSQL을 쓰면 상당히 효율적이다
-
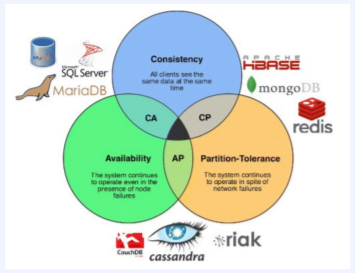
분산시스템에서 다음과 같은 세가지 조건을 모두 만족하는 시스템은 존재할 수 없음을 증명한 정리
-
C (Consistency) : 모든 노드들이 같은 시점에 같은 값을 볼 수 있다(또는 에러). 일관성은 동시성 또는 동일성이라고도 하며 다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것을 의미한다. 이것은 관계형 데이터베이스가 지원하는 가장 기본적인 기능이지만 일관성을 지원하지 않는 NoSQL 을 사용한다면 데이터의 일관성이 느슨하게 처리되어 동일한 데이터가 나타나지 않을 수 있다. 느슨하게 처리된다는 것은 데이터의 변경을 시간의 흐름에 따라 여러 노드에 전파하는 것을 말한다. 이러한 방법을 최종적으로 일관성이 유지된다고 하여 최종 일관성 또는 궁극적 일관성을 지원한다고 한다. 각 NoSQL 들은 분산 노드 간의 데이터 동기화를 위해서 두 가지 방법을 사용한다. 첫번째로 데이터의 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장하는 동기식 방법이 있다. 그만큼 느린 응답시간을 보이지만 데이터의 정합성을 보장한다. 두번째로 메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음, 특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화하는 비동기식 방법이 있다. 빠른 응답시간을 보인다는 장점이 있지만, 쓰기 노드에 장애가 발생하였을 경우 데이터가 손실될 수 있다.
-
A (Availability) : 모든 request는 에러 없이 response를 받을 수 있다(최신 값을 return함은 보장 안함). 가용성이란 모든 클라이언트의 읽기와 쓰기 요청에 대하여 항상 응답이 가능해야 함을 보증하는 것이며 내고장성이라고도 한다. 내고장성을 가진 NoSQL 은 클러스터 내에서 몇 개의 노드가 망가지더라도 정상적인 서비스가 가능하다. 몇몇 NoSQL 은 가용성을 보장하기 위해 데이터 복제(Replication)을 사용한다. 동일한 데이터를 다중 노드에 중복 저장하여 그 중 몇 대의 노드가 고장나도 데이터가 유실되지 않도록 하는 방법이다. 데이터 중복 저장 방법에는 동일한 데이터를 가진 저장소를 하나 더 생성하는 Master-Slave 복제 방법과 데이터 단위로 중복 저장하는 Peer-to-Peer 복제 방법이 있다.
-
P (Partition tolerance) : network partition이 나서 message의 분실이 발생해도 시스템이 계속 동작해야 한다. 분할 허용성이란 지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서 두 지역 간의 네트워크가 단절되거나 네트워크 데이터의 유실이 일어나더라도 각 지역 내의 시스템은 정상적으로 동작해야 함을 의미한다.
-
NoSQL은 consistency와 availability을 동시에 제공하지 않는다 - 불가능
Key-Value Model,Document Model,Column Model,Graph Model로 분류할 수 있다
가장 기본적인 형태의 NoSQL이며 키 하나로 데이터 하나를 저장하고 조회할 수 있는 단일 키-값 구조를 갖는다. 단순한 저장구조로 인하여 복잡한 조회 연산을 지원하지 않는다. 또한 고속 읽기와 쓰기에 최적화된 경우가 많다. 사용자의 프로필 정보, 웹 서버 클러스터를 위한 세션 정보, 장바구니 정보, URL 단축 정보 저장 등에 사용한다. 하나의 서비스 요청에 다수의 데이터 조회 및 수정 연산이 발생하면 트랜잭션 처리가 불가능하여 데이터 정합성을 보장할 수 없다.
상당한 유연성을 제공하며 동일 데이터에서 메모리를 훨씬 덜 이용하므로 부하관리에 큰 이점이 있다. 단순한 저장구조를 가지기 때문에 복잡한 조회 연산을 지원하지 않는다. 고속 읽기와 쓰기에 최적화된 경우가 많다. 메모리를 저장소로 쓰는 경우, 아주 빠른 get과 put을 지원한다. value는 문자열이나 정수와 같은 원시 타입이 들어갈 수 있고, 또 다른 key/value가 들어갈 수도 있다
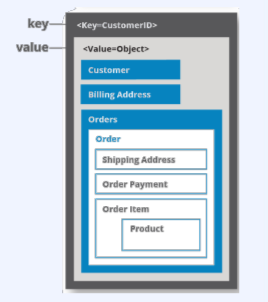
ex) CouchDB, Redis, Dynamo, Azure Customs DB
사용 예제) session 정보 제공, 사용자 profile 등
키-값 모델을 개념적으로 확장한 구조로 하나의 키에 하나의 구조화된 문서를 저장(value에 Document라는 타입을 저장한다. XML, JSON, YAML 등이다)하고 조회한다. 논리적인 데이터 저장과 조회 방법이 관계형 데이터베이스와 유사하다. 키는 문서에 대한 ID로 표현된다. 또한 저장된 문서를 컬렉션으로 관리하며 문서 저장과 동시에 문서 ID에 대한 인덱스를 생성한다. 문서 ID에 대한 인덱스를 사용하여 O(1)시간 안에 문서를 조회할 수 있다
대부분의 문서 모델 NoSQL은 B트리 인덱스를 사용하여 2차 인덱스를 생성한다. B 트리는 크기가 커지면 커질수록 새로운 데이터를 입력하거나 삭제할 때 성능이 떨어지게 된다. 그렇기 때문에 읽기와 쓰기의 비율이 7:3 정도일 때 가장 좋은 성능을 보인다. 중앙 집중식 로그 저장, 타임라인 저장, 통계 정보 저장 등에 사용된다.
복잡한 데이터 구조 표현이 가능하다. Document id 또는 속성값 기준으로 인덱스를 생성한다. key값의 range에 대한 효율적인 연산이 가능해지므로 이에 대한 쿼리를 제공한다. Sorting, Join, Grouping 등이 가능하다. 쿼리 처리에 있어서 데이터를 파싱해서 연산해야 하므로 overhead가 key-value 모델보다 크다.
테이블의 스키마가 상당히 유동적으로 이루어질 수 있어서 레코드마다 각각 다른 스키마를 가질 수 있다. XML이나 JSON같은 도큐먼트를 이용해서 레코드를 저장한다 하여 DOCUMENT DATABASE라고 불린다. 트리형 구조로 데이터를 만들고 조회하기 딱 좋은 데이터베이스이다. 대표적으로 잘 알고있는 MongoDB, CouchDB, Azure Cosmos DB가 있다.
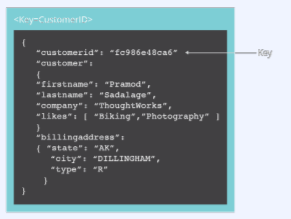
- JSON같은 semi-structured data인 document를 저장/조회하는 데이터베이스
- Key-Value store의 하위 클래스
- Key-Value store와 달리 데이터베이스 내부에서 최적화를 지원하기 위해 document가 가진 metadata 정보 이용
MongoDB 예시

ex) - MongoDB, Azure CosmosDB, Azure DocumentDB
하나의 키에 여러 개의 컬럼 이름과 컬럼 값의 쌍으로 이루어진 데이터를 저장하고 조회한다. 모든 컬럼은 항상 타임 스탬프 값과 함께 저장된다
구글의 빅테이블이 대표적인 예로 차후 컬럼형 NoSQL은 빅테이블의 영향을 받았다. 이러한 이유로 Row key, Column key, Column family 같은 빅테이블 개념이 공통적으로 사용된다. 저장의 기본 단위는 컬럼으로 컬럼은 컬럼 이름과 컬럼 값, 타임스탬프로 구성된다. 이러한 컬럼들의 집합이 로우(Row)이며, 로우키(Row key)는 각 로우를 유일하게 식별하는 값이다. 이러한 로우들의 집합은 키 스페이스(Key Space)가 된다
대부분의 컬럼 모델 NoSQL은 쓰기와 읽기 중에 쓰기에 더 특화되어 있다. 데이터를 먼저 커밋로그와 메모리에 저장한 후 응답하기 때문에 빠른 응답속도를 제공한다. 그렇기 때문에 읽기 연산 대비 쓰기 연산이 많은 서비스나 빠른 시간 안에 대량의 데이터를 입력하고 조회하는 서비스를 구현할 때 가장 좋은 성능을 보인다. 채팅 내용 저장, 실시간 분석을 위한 데이터 저장소 등의 서비스 구현에 적합하다.
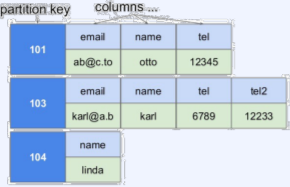
- RDBMS와 비슷하게 wide-column store도 table, column, row 개념을 사용
- RDBMS와의 차이점 : 각 rows가 다른 column list를 가질 수 있다
- 2차원의 key-value store로 생각할 수 있다
ex) AWS DynamoDB, Cassandra, Google Bigtable
node들과 relationship들로 구성된 개념이다. key/value store 방식이며 모든 노드는 끊기지 않고 연결되어 있어야 한다. realtionship은 direction, type, start node, end node에 대한 속성들을 가진다.
일반적으로 관계형 데이터베이스보다 퍼포먼스가 뛰어나며 유연한 데이터 처리와 유지보수가 용이한 것이 장점이다. SNS 구축에 사용하기 좋은 데이터베이스이다.
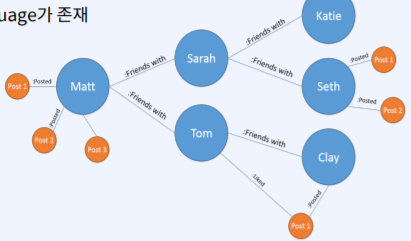
- 데이터를 node, edge 및 property를 가지고 graph structure를 이용하여 저장하는 데이터베이스
- Graph에서 데이터를 효율적으로 쿼리하기 위한 graph 데이터베이스 전용 query language가 존재 : Cypher, Gremlin
ex) Neo4j, infinite Graph
두 데이터베이스를 비교할 때 중요한 Scaling 개념도 존재한다
데이터베이스 서버의 확장성은 수직적 확장과 수평적 확장으로 나누어진다
- 수직적 확장 : 단순히 데이터베이스 서버의 성능을 향상시키는 것(ex. CPU 업그레이드)
- 수평적 확장 : 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산됨을 의미한다(하나의 데이터베이스에서 작동하지만, 여러 호스트에서 작동)
데이터 저장 방식으로 인해 SQL DB는 일반적으로 수직적 확장만 지원한다
수평적 확장은 NoSQL DB에서만 가능하다
둘 중에 뭘 선택하느냐에 대한 정답은 없다. 어떤 데이터를 다루느냐에 따라 원하는 방식에 맞게 선택을 고려하면 된다
- 명확하게 정의된 스키마, 데이터 무결성 보장
- 관계는 각 데이터를 중복 없이 한번만 저장
- 덜 유연하다. 데이터 스키마를 사전에 계획하고 알려야 한다(나중에 수정하기 힘들다)
- 관계를 맺고 있어서 조인문이 많은 복잡한 쿼리가 만들어질 수 있다
- 대체로 수직적 확장만 가능하다
- 스키마가 없어서 유연하다. 언제든지 저장된 데이터를 조정하고 새로운 필드 추가가 가능하다
- 데이터는 애플리케이션이 필요로 하는 형식으로 저장된다. 데이터를 읽어오는 속도가 빨라진다
- 수직 및 수평 확장이 가능해서 애플리케이션이 발생시키는 모든 읽기/쓰기 요청 처리가 가능하다
- 더 큰 데이터 볼륨을 처리하고 대기 시간을 줄이고 처리량을 개선하는 몇 가지 조합을 통해 데이터 액세스 성능을 개선
- 유연성으로 인해 데이터 구조 결정을 미루게 될 수 있다
- 데이터 중복을 계속 업데이트 해야 한다
- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정시 모든 컬렉션에서 수행해야 한다(SQL에서는 중복 데이터가 없으므로 한번만 수행이 가능)
- 복잡한 relationship이 있는 테이블이 있는 경우 JOIN을 제공하지 않기 때문에 적합하지 않다
- 관계를 맺고 있는 데이터가 자주 변경되는 애플리케이션의 경우
- NoSQL에서는 여러 컬렉션을 모두 수정해야 하기 때문에 비효율적
- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
- 정확한 데이터 구조를 알 수 없거나 변경/확장이 될 수 있는 경우
- 읽기를 자주 하지만, 데이터 변경은 자주 없는 경우
- 데이터베이스를 수평으로 확장해야 하는 경우(막대한 양의 데이터를 다뤄야 하는 경우)
- very large semi-structured data를 처리하는 애플리케이션에 적합 - Log Analysis, Social Networking Feeds, Time-based data
| SQL | NoSQL |
|---|---|
| SQL 데이터베이스는 주로 관계형 데이터베이스이다 | NoSQL 데이터베이스는 주로 비관계형 또는 분산 데이터베이스이다 |
| 오래된 기술 | 비교적 젊은 기술 |
| SQL은 행 및 열 형식의 테이블 기반이며 표준 스키마 정의를 엄격히 준수해야 한다. 다중 행 트랜잭션이 필요한 응용 프로그램에 더 나온 옵션이다 | NoSQL 데이터베이스는 문서, 키-값, 그래프 또는 열을 기반으로 할 수 있으며 표준 스키마 정의를 고수할 필요가 없다 |
| 구조화된 데이터를 위해 잘 설계된 사전정의된 스키마가 있다 | 구조화되지 않은 데이터에 대한 동적 스키마가 있다. 데이터는 미리 정의된 구조없이 유연하게 저장할 수 있다 |
| SQL은 정규화된 스키마를 선호한다 | NoSQL은 비정규화된 스키마를 선호한다 |
| 확장 비용이 많이 든다 | 관계형 데이터베이스에 비해 확장 비용이 저렴하다 |
| SQL은 수직 확장이 가능하다. 단일 서버에서 하드웨어 용량(CPU, RAM, SSD)을 늘려 확장할 수 있다 | NoSQL은 수평 확장이 가능하다. 대규모로드를 관리하고 힙을 줄이기 위해 인프라에 더 많은 서버를 추가하여 확장할 수 있다 |
| SQL에는 쿼리 처리를 위한 표준 인터페이스가 있으므로 복잡한 쿼리에 적합하다. SQL 쿼리 구문이 수정되었습니다 | NoSQL에는 쿼리 처리를 위한 표준 인터페이스가 없기 때문에 복잡한 쿼리에는 적합하지 않다. NoSQL의 쿼리는 SQL쿼리만큼 강력하지 않다. 이를 UnQL이라고하며 구조화되지 않은 쿼리 언어를 사용하는 구문은 구문마다 다르다 |
| SQL은 계층적 데이터 저장소에 적합하지 않다 | NoSQL은 데이터 저장을 위한 키-값 쌍 방버을 따르므로 계층적 데이터 저장에 가장 적합하다 |
| 상업적 관점에서 SQL은 일반적으로 오픈 소스 또는 폐쇄 소스로 분류된다 | 키-값 저장소, 문서 저장소, 그래프 저장소, 열 저장소 및 XML 저장소로 데이터를 저장하는 방식에 따라 분류된다 |
| SQL은 ACID 속성(원자성, 일관성, 격리성, 내구성)을 올바르게 따른다 | NoSQL은 CAP정리를 올바르게 따른다 |
| SQL은 새 데이터를 추가하려면 스키마 변경과 같은 일부 변경이 필요하다 | 새 데이터는 이전 단계가 필요하지 않으므로 NoSQL에 쉽게 삽입할 수 있다 |
| 모든 SQL에 대해 우수한 공급 업체 및 커뮤니티 지원이 제공된다 | NoSQL에는 제한된 커뮤니티 지원만 사용할 수 있다 |
| 높은 트랜잭션 기반 어플리케이션에 가장 적합하다 | 무거운 트랜잭션 목적으로 NoSQL을 사용할 수 있다. 그러나 이것은 이것에 가장 적합하지 않다 |
| 계층적 데이터 저장에는 적합하지 않다 | 계층적 데이터 저장 및 대용량 데이터 세트(예 : 빅데이터) 저장에 적합하다 |
SQL과 NoSQL 데이터베이스의 선택은 비즈니스 요구 사항, 구조적 설계 등 다양한 경우에 따라 달라진다. 따라서 어플리케이션의 특성에 맞는 데이터베이스를 선택하는 것이 중요하다. 현재 NoSQL은 빅 데이터를 통합할 수 있는 용량, 저렴한 비용(분산된 환경에 데이터를 저장하므로 즉 여러 서버에 데이터를 나누어 저장하므로 큰 비용없이 스케일링이 가능하다), 쉬운 확장성 및 오픈소스 기능으로 인기가 많다. 또한 모델링이 필요하지 않아 시간과 노력이 절약된다. 하지만 비교적 젊은 기술이며 표준화가 부족하다. ACID 규정 준수 부족(더 빠른 데이터 액세스를 제공하기 위해 내장 보안 기능이 거의 없다. 기밀성과 무결성 속성이 부족하다. NoSQL 자체적으로 보안 기능을 제공하지 않으므로 어플리케이션의 보안 기능에 의존해야 한다. RDBMS보다 보안 공격에 더 취약하다)도 NoSQL의 문제이다. SQL은 미리 정의된 스키마가 있다. 정규화를 사용할 수 있으므로 중복성을 제거하고 데이터를 더 나은 방식으로 구성하는 데도 도움이 된다. 하지만 인터페이스 프로세스가 복잡하며 SQL은 객체이므로 공간을 차지한다. 확장을 위해서는 하드웨어를 늘려야하므로 빅 데이터를 처리하는데 비용이 많이 들고, 테이블이 삭제되면 뷰가 비활성화된다는 단점이 있다. 각각의 장단점을 잘 살펴 알맞은 DB를 선택해야 한다