浏览器解析原理 #18
Description
浏览器解析文档流程
当浏览器通过请求获取到 HTML/SVG/XHTML 文档后,一般会通过如下流程解析生成最后呈现的页面。

webkit 内核渲染原理:
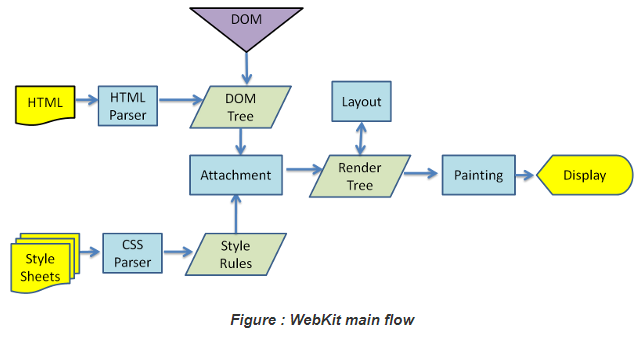
1. 构造 DOM 树
这一阶段又包含两步操作:HTML/SVG/XHTML 的解析, css 解析以及 js 等脚本解析。
1.1 HTML/SVG/XHTML 解析
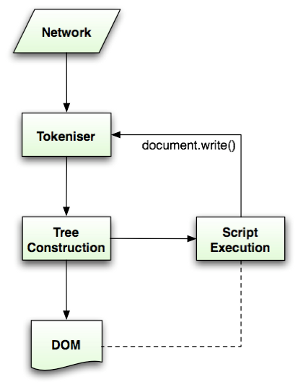
浏览器会根据响应内容解析文档结构使之变为 DOM 树。不同于其语言的解析器,自上而下或自下而上的解析规则并不适用于 HTML 语法。因为:
- 浏览器对
HTML有较高的容错率,很多无效的HTML标签都能被浏览器HTML解析器所兼容。 HTML结构会受到脚本语言的影响,是动态变化的,解析器获取的内容并不是静态不变的。
总体来说,HTML 解析器在构造 DOM 树的过程中主要有两步:
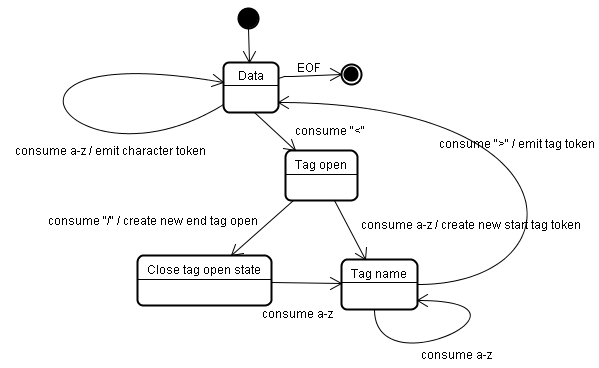
标签标记化:
通过词法分析将 HTML 中有特殊含义的字段标记出来,比如起始标签、结束标签、属性名和属性值等等。标记化算法的基本思路是基于一个有限状态机,根据 HTML 输入不断更新状态机状态,然后根据状态提取标记。
树形结构构造:
根据提取出来的标记,构造出完整的 DOM 树。
1.2 css 解析
浏览器会把请求到的 css 资源解析成对应的 css 规则树。
通常 css 解析不会阻塞 DOM 树解析,因此往往会把样式表放到文档前面,让样式和 DOM 并行解析。在一些特殊场景比如 js 脚本需要访问样式表而样式表没有加载完成时,可能会抛出异常。为了防止出现类似错误,诸如 webkit 等浏览器会在样式还未加载完成时候阻塞脚本的继续执行。
1.3 js 脚本解析
在遇到 <script> 标签时,浏览器默认会从文档解析转成 js 脚本解析,此时文档解析会被挂起,只有当脚本解析完成后才会继续文档。如果 <script> 是外链,则必须等到资源完全响应才能继续执行脚本。现代浏览器可以通过异步加载脚本来实现非阻塞执行脚本。
在执行脚本过程中,浏览器会新起一个子线程用来加载剩余未加载的资源,该子线程只是单纯的加载资源并不会修改 DOM 树,只有主进程才能修改,子进程加载资源的过程称为预加载。
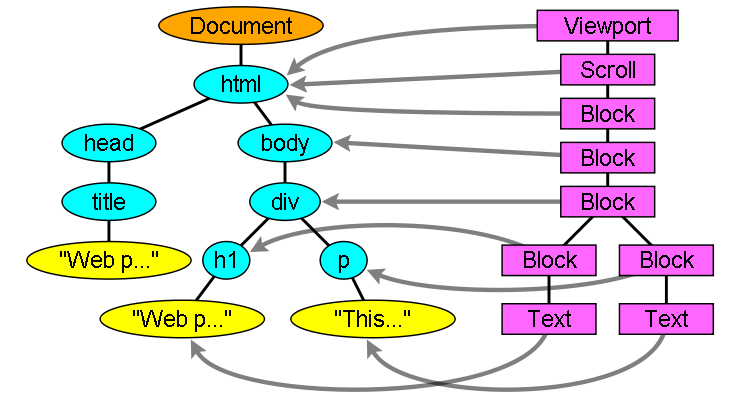
2. 构造渲染树
结合之前解析得到的 DOM 树和 css 规则树,浏览器会继续解析生成渲染树。渲染树是浏览器最后渲染到页面上的结构。DOM 树和渲染树是两种树形结构,其节点并非一一对应,举例:
<header>标签和display:none的标签不会放到渲染树结构中。- 一些标签一个就对应着若干矩形盒模型,这些矩形块都会出现渲染树中。
- 对于脱离文档流的标签,可能出现在渲染树中的相对位置也会与
DOM树种的不同。
3. 布局
渲染树只是确定了最终呈现在页面的内容,更进一步,需要计算渲染树节点在页面上的最终位置。
大部分情况下,浏览器会在一个事件流内把所有节点的位置都计算出来,因为后布局的元素不会对之前布局的元素位置有影响,所以浏览器可以根据从左到右,自上而下的方式布局元素,这种做法对于某些元素可能并不适用,比如 table。
4. 绘制
该阶段通过调用浏览器底层 UI 接口把渲染树绘制到页面上展示给用户。
参考文献:
https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/#Introduction